 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Learning Expectation Maximization
Paper and Code
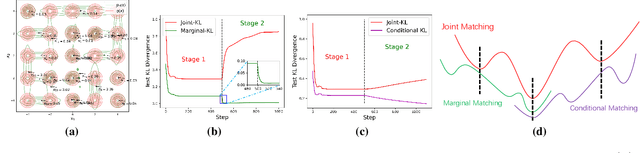
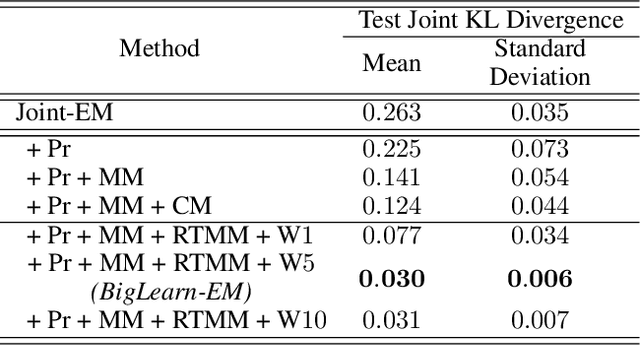
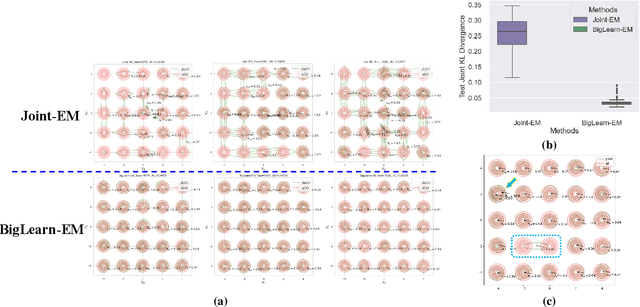
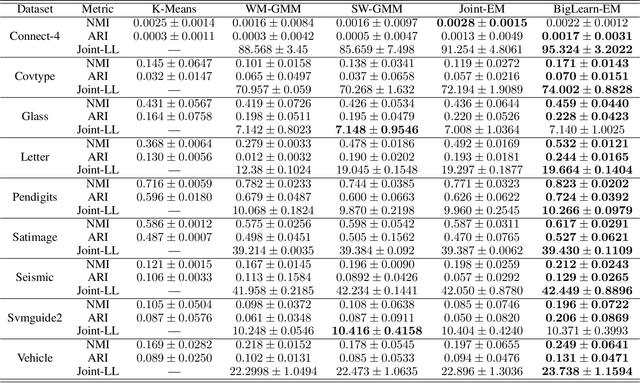
Mixture models serve as one fundamental tool with versatile applications. However, their training techniques, like the popular Expectation Maximization (EM) algorithm, are notoriously sensitive to parameter initialization and often suffer from bad local optima that could be arbitrarily worse than the optimal. To address the long-lasting bad-local-optima challenge, we draw inspiration from the recent ground-breaking foundation models and propose to leverage their underlying big learning principle to upgrade the EM. Specifically, we present the Big Learning EM (BigLearn-EM), an EM upgrade that simultaneously performs joint, marginal, and orthogonally transformed marginal matchings between data and model distributions. Through simulated experiments, we empirically show that the BigLearn-EM is capable of delivering the optimal with high probability; comparisons on benchmark clustering datasets further demonstrate its effectiveness and advantages over existing techniques. The code is available at https://github.com/YulaiCong/Big-Learning-Expectation-Maximization.