 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyCoT: Hyperspectral Compression Transformer with an Efficient Training Strategy
Aug 16, 2024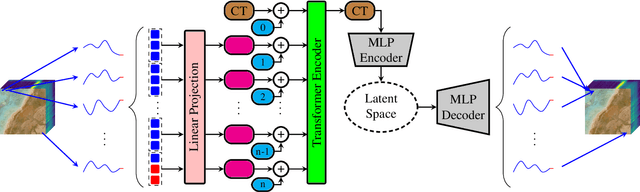
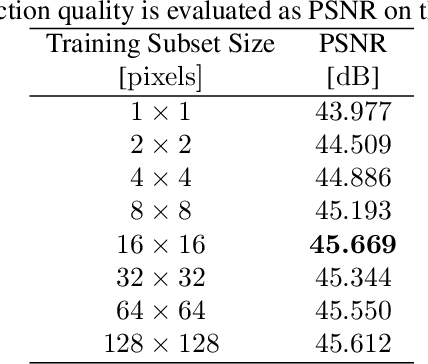
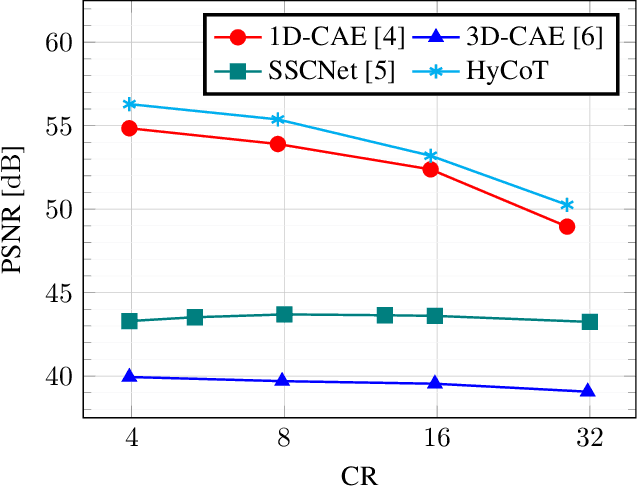
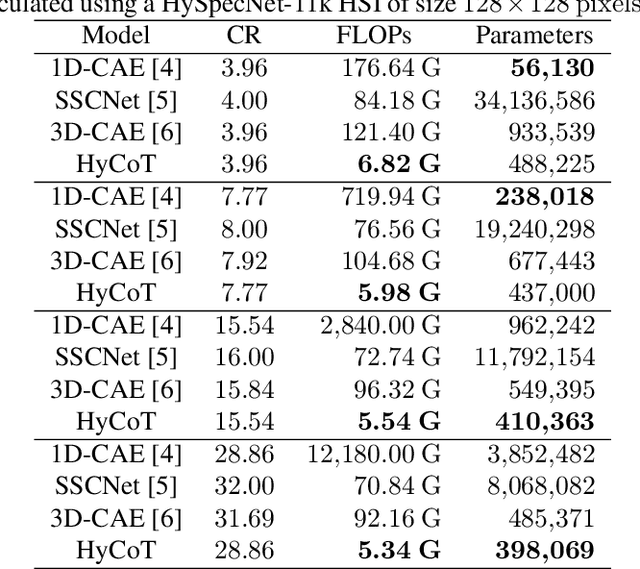
The development of learning-based hyperspectral image (HSI) compression models has recently attracted significant interest. Existing models predominantly utilize convolutional filters, which capture only local dependencies. Furthermore, they often incur high training costs and exhibit substantial computational complexity. To address these limitations, in this paper we propose Hyperspectral Compression Transformer (HyCoT) that is a transformer-based autoencoder for pixelwise HSI compression. Additionally, we introduce an efficient training strategy to accelerate the training process. Experimental results on the HySpecNet-11k dataset demonstrate that HyCoT surpasses the state-of-the-art across various compression ratios by over 1 dB with significantly reduced computational requirements. Our code and pre-trained weights are publicly available at https://git.tu-berlin.de/rsim/hycot .
HySpecNet-11k: A Large-Scale Hyperspectral Dataset for Benchmarking Learning-Based Hyperspectral Image Compression Methods
Jun 02, 2023


The development of learning-based hyperspectral image compression methods has recently attracted great attention in remote sensing. Such methods require a high number of hyperspectral images to be used during training to optimize all parameters and reach a high compression performance. However, existing hyperspectral datasets are not sufficient to train and evaluate learning-based compression methods, which hinders the research in this field. To address this problem, in this paper we present HySpecNet-11k that is a large-scale hyperspectral benchmark dataset made up of 11,483 nonoverlapping image patches. Each patch is a portion of 128 $\times$ 128 pixels with 224 spectral bands and a ground sample distance of 30 m. We exploit HySpecNet-11k to benchmark the current state of the art in learning-based hyperspectral image compression by focussing our attention on various 1D, 2D and 3D convolutional autoencoder architectures. Nevertheless, HySpecNet-11k can be used for any unsupervised learning task in the framework of hyperspectral image analysis. The dataset, our code and the pre-trained weights are publicly available at https://hyspecnet.rsim.berlin
Generative Adversarial Networks for Spatio-Spectral Compression of Hyperspectral Images
May 15, 2023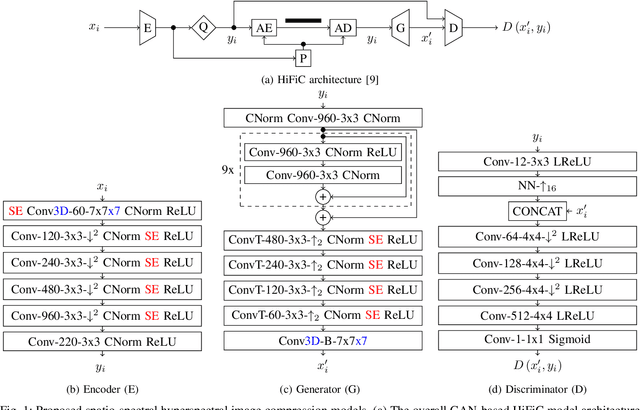



Deep learning-based image compression methods have led to high rate-distortion performances compared to traditional codecs. Recently, Generative Adversarial Networks (GANs)-based compression models, e.g., High Fidelity Compression (HiFiC), have attracted great attention in the computer vision community. However, most of these works aim for spatial compression only and do not consider the spatio-spectral redundancies observed in hyperspectral images (HSIs). To address this problem, in this paper, we adapt the HiFiC spatial compression model to perform spatio-spectral compression of HSIs. To this end, we introduce two new models: i) HiFiC using Squeeze and Excitation (SE) blocks (denoted as HiFiC$_{SE}$); and ii) HiFiC with 3D convolutions (denoted as HiFiC$_{3D}$). We analyze the effectiveness of HiFiC$_{SE}$ and HiFiC$_{3D}$ in exploiting the spatio-spectral redundancies with channel attention and inter-dependency analysis. Experimental results show the efficacy of the proposed models in performing spatio-spectral compression and reconstruction at reduced bitrates and higher reconstruction quality when compared to JPEG 2000 and the standard HiFiC spatial compression model. The code of the proposed models is publicly available at https://git.tu-berlin.de/rsim/HSI-SSC .