 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Nov 02, 2020
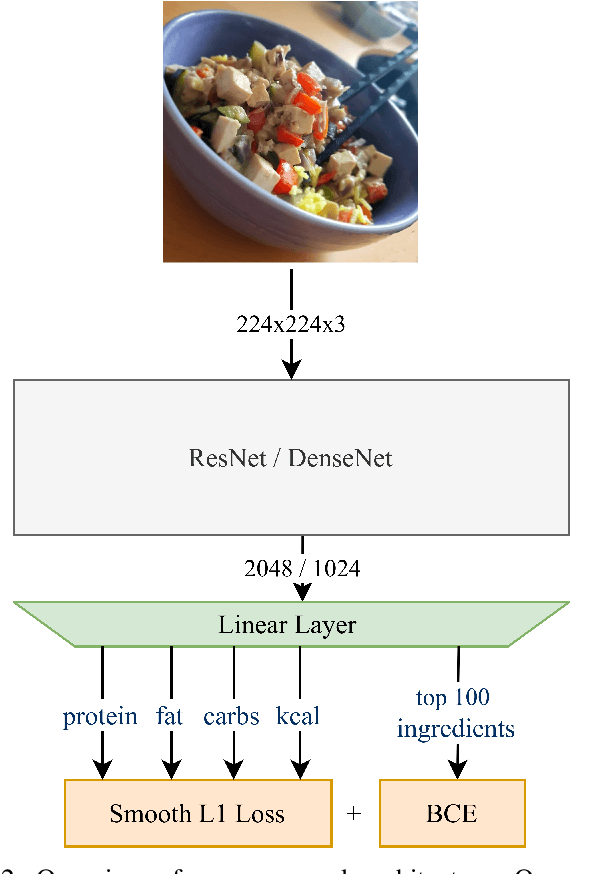
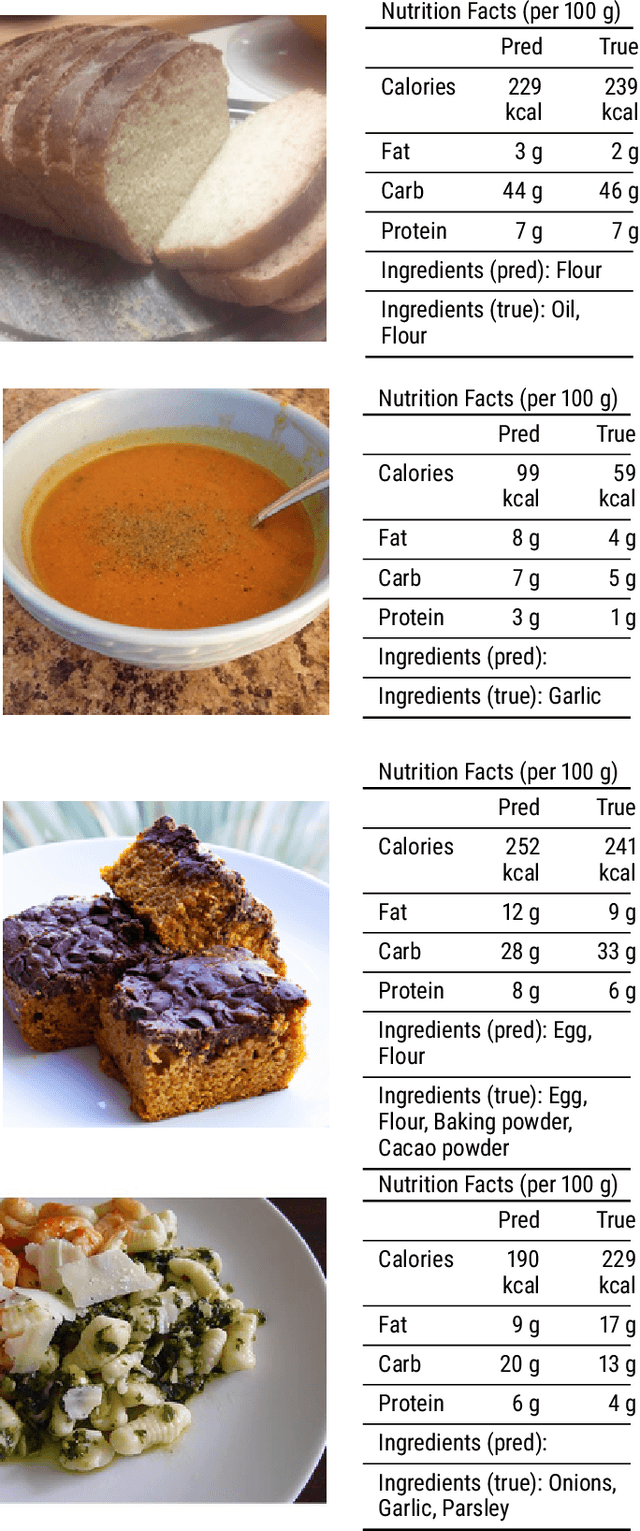
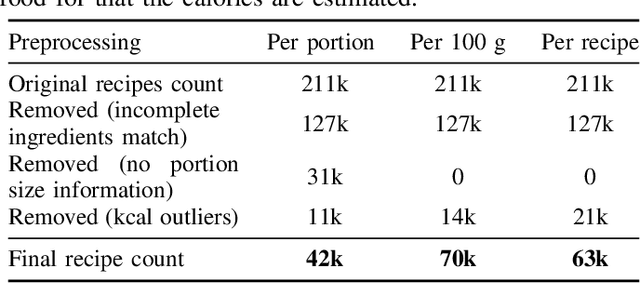
A rapidly growing amount of content posted online, such as food recipes, opens doors to new exciting applications at the intersection of vision and language. In this work, we aim to estimate the calorie amount of a meal directly from an image by learning from recipes people have published on the Internet, thus skipping time-consuming manual data annotation. Since there are few large-scale publicly available datasets captured in unconstrained environments, we propose the pic2kcal benchmark comprising 308,000 images from over 70,000 recipes including photographs, ingredients and instructions. To obtain nutritional information of the ingredients and automatically determine the ground-truth calorie value, we match the items in the recipes with structured information from a food item database. We evaluate various neural networks for regression of the calorie quantity and extend them with the multi-task paradigm. Our learning procedure combines the calorie estimation with prediction of proteins, carbohydrates, and fat amounts as well as a multi-label ingredient classification. Our experiments demonstrate clear benefits of multi-task learning for calorie estimation, surpassing the single-task calorie regression by 9.9%. To encourage further research on this task, we make the code for generating the dataset and the models publicly available.
Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor
Jun 02, 2017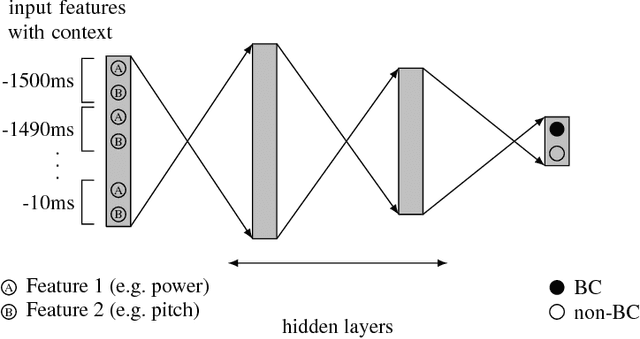
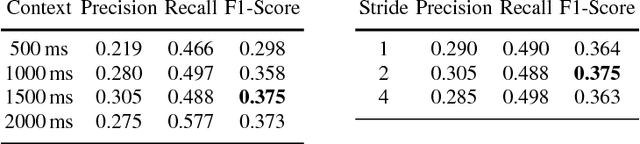
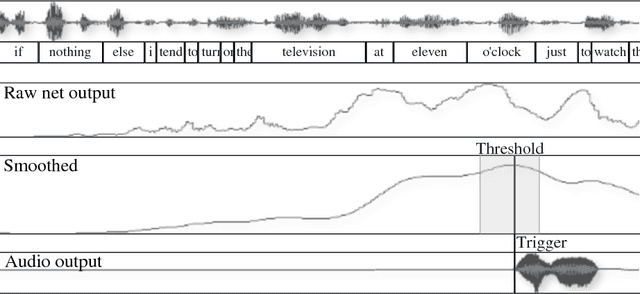

Using supporting backchannel (BC) cues can make human-computer interaction more social. BCs provide a feedback from the listener to the speaker indicating to the speaker that he is still listened to. BCs can be expressed in different ways, depending on the modality of the interaction, for example as gestures or acoustic cues. In this work, we only considered acoustic cues. We are proposing an approach towards detecting BC opportunities based on acoustic input features like power and pitch. While other works in the field rely on the use of a hand-written rule set or specialized features, we made use of artificial neural networks. They are capable of deriving higher order features from input features themselves. In our setup, we first used a fully connected feed-forward network to establish an updated baseline in comparison to our previously proposed setup. We also extended this setup by the use of Long Short-Term Memory (LSTM) networks which have shown to outperform feed-forward based setups on various tasks. Our best system achieved an F1-Score of 0.37 using power and pitch features. Adding linguistic information using word2vec, the score increased to 0.39.