 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-sensitive Activity Recognition: a Reliability Benchmark and the CARING Models
Jan 02, 2021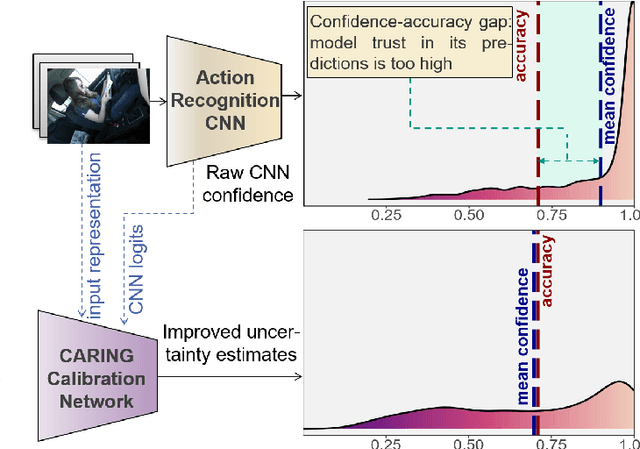
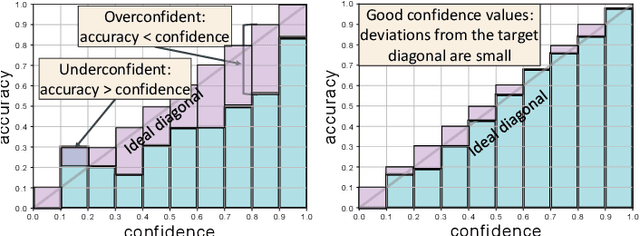
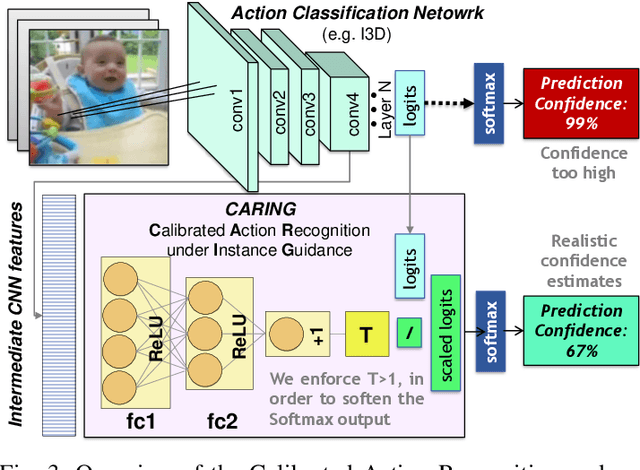
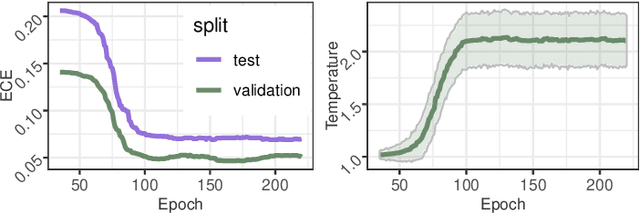
Beyond assigning the correct class, an activity recognition model should also be able to determine, how certain it is in its predictions. We present the first study of how welthe confidence values of modern action recognition architectures indeed reflect the probability of the correct outcome and propose a learning-based approach for improving it. First, we extend two popular action recognition datasets with a reliability benchmark in form of the expected calibration error and reliability diagrams. Since our evaluation highlights that confidence values of standard action recognition architectures do not represent the uncertainty well, we introduce a new approach which learns to transform the model output into realistic confidence estimates through an additional calibration network. The main idea of our Calibrated Action Recognition with Input Guidance (CARING) model is to learn an optimal scaling parameter depending on the video representation. We compare our model with the native action recognition networks and the temperature scaling approach - a wide spread calibration method utilized in image classification. While temperature scaling alone drastically improves the reliability of the confidence values, our CARING method consistently leads to the best uncertainty estimates in all benchmark settings.
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Nov 02, 2020
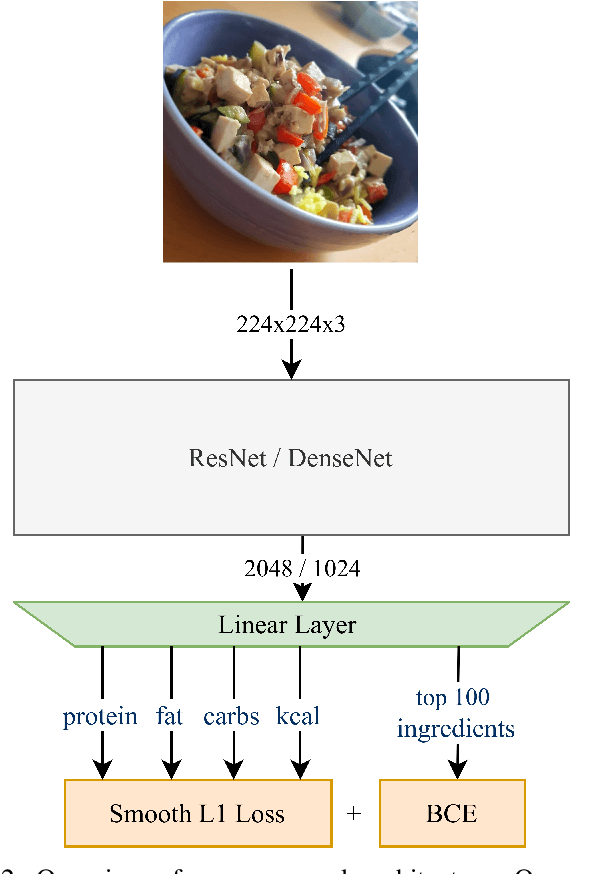
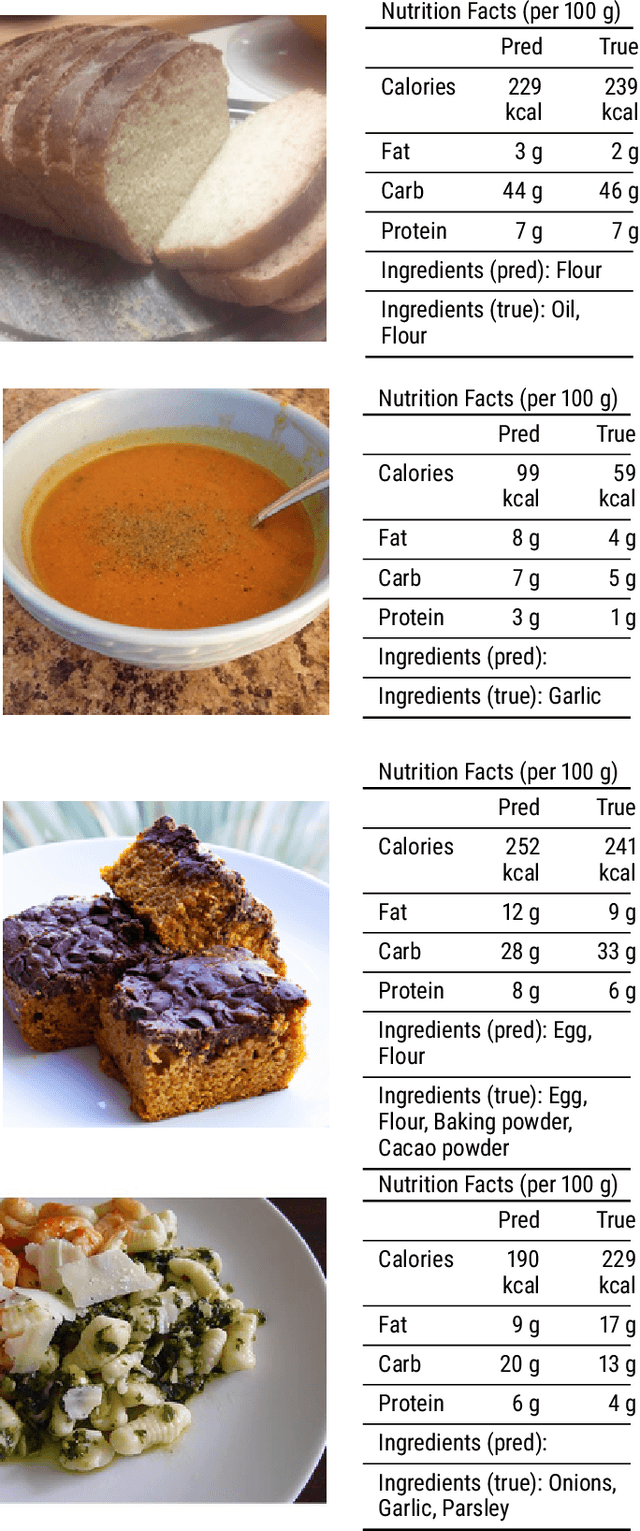
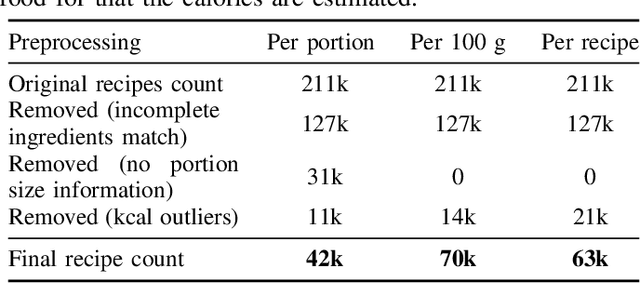
A rapidly growing amount of content posted online, such as food recipes, opens doors to new exciting applications at the intersection of vision and language. In this work, we aim to estimate the calorie amount of a meal directly from an image by learning from recipes people have published on the Internet, thus skipping time-consuming manual data annotation. Since there are few large-scale publicly available datasets captured in unconstrained environments, we propose the pic2kcal benchmark comprising 308,000 images from over 70,000 recipes including photographs, ingredients and instructions. To obtain nutritional information of the ingredients and automatically determine the ground-truth calorie value, we match the items in the recipes with structured information from a food item database. We evaluate various neural networks for regression of the calorie quantity and extend them with the multi-task paradigm. Our learning procedure combines the calorie estimation with prediction of proteins, carbohydrates, and fat amounts as well as a multi-label ingredient classification. Our experiments demonstrate clear benefits of multi-task learning for calorie estimation, surpassing the single-task calorie regression by 9.9%. To encourage further research on this task, we make the code for generating the dataset and the models publicly available.
Detective: An Attentive Recurrent Model for Sparse Object Detection
Apr 25, 2020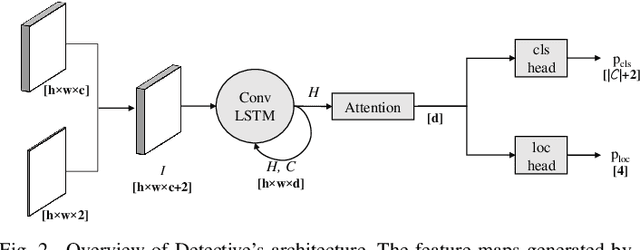
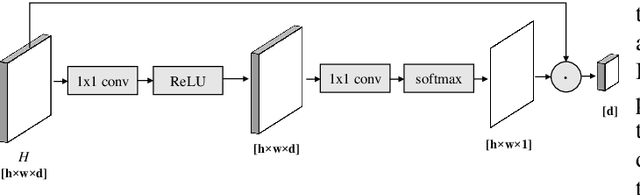
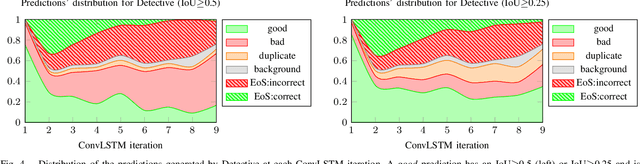
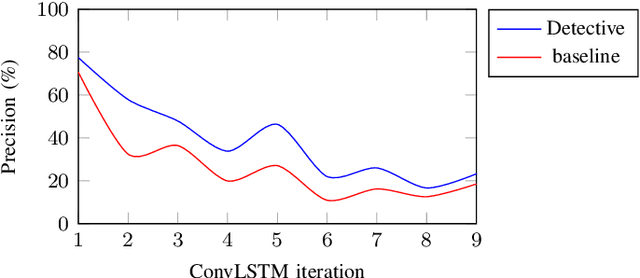
In this work, we present Detective - an attentive object detector that identifies objects in images in a sequential manner. Our network is based on an encoder-decoder architecture, where the encoder is a convolutional neural network, and the decoder is a convolutional recurrent neural network coupled with an attention mechanism. At each iteration, our decoder focuses on the relevant parts of the image using an attention mechanism, and then estimates the object's class and the bounding box coordinates. Current object detection models generate dense predictions and rely on post-processing to remove duplicate predictions. Detective is a sparse object detector that generates a single bounding box per object instance. However, training a sparse object detector is challenging, as it requires the model to reason at the instance level and not just at the class and spatial levels. We propose a training mechanism based on the Hungarian algorithm and a loss that balances the localization and classification tasks. This allows Detective to achieve promising results on the PASCAL VOC object detection dataset. Our experiments demonstrate that sparse object detection is possible and has a great potential for future developments in applications where the order of the objects to be predicted is of interest.
Relaxed Earth Mover's Distances for Chain- and Tree-connected Spaces and their use as a Loss Function in Deep Learning
Nov 22, 2016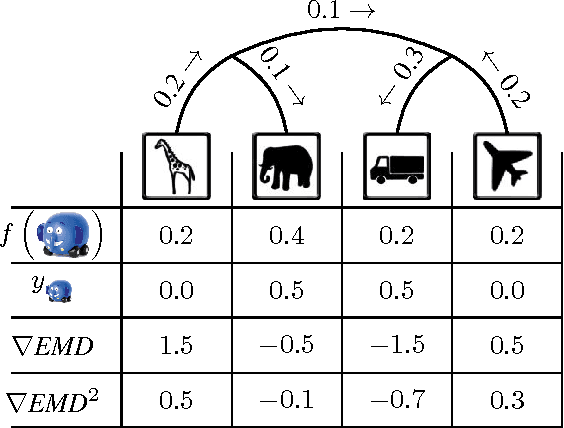

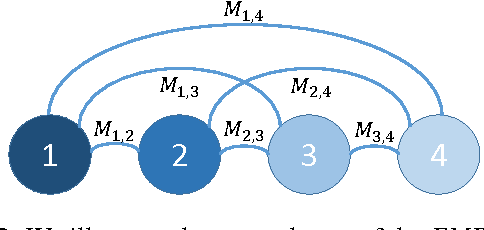
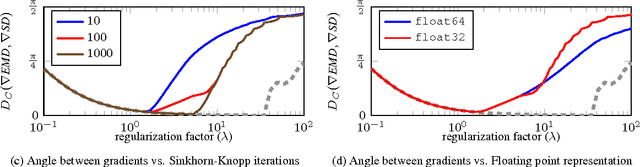
The Earth Mover's Distance (EMD) computes the optimal cost of transforming one distribution into another, given a known transport metric between them. In deep learning, the EMD loss allows us to embed information during training about the output space structure like hierarchical or semantic relations. This helps in achieving better output smoothness and generalization. However EMD is computationally expensive.Moreover, solving EMD optimization problems usually require complex techniques like lasso. These properties limit the applicability of EMD-based approaches in large scale machine learning. We address in this work the difficulties facing incorporation of EMD-based loss in deep learning frameworks. Additionally, we provide insight and novel solutions on how to integrate such loss function in training deep neural networks. Specifically, we make three main contributions: (i) we provide an in-depth analysis of the fastest state-of-the-art EMD algorithm (Sinkhorn Distance) and discuss its limitations in deep learning scenarios. (ii) we derive fast and numerically stable closed-form solutions for the EMD gradient in output spaces with chain- and tree- connectivity; and (iii) we propose a relaxed form of the EMD gradient with equivalent computational complexity but faster convergence rate. We support our claims with experiments on real datasets. In a restricted data setting on the ImageNet dataset, we train a model to classify 1000 categories using 50K images, and demonstrate that our relaxed EMD loss achieves better Top-1 accuracy than the cross entropy loss. Overall, we show that our relaxed EMD loss criterion is a powerful asset for deep learning in the small data regime.