 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMB: LLM-based Audio Captioning with Modality Gap Bridging via Cauchy-Schwarz Divergence
Jan 08, 2026Automated Audio Captioning aims to describe the semantic content of input audio. Recent works have employed large language models (LLMs) as a text decoder to leverage their reasoning capabilities. However, prior approaches that project audio features into the LLM embedding space without considering cross-modal alignment fail to fully utilize these capabilities. To address this, we propose LAMB, an LLM-based audio captioning framework that bridges the modality gap between audio embeddings and the LLM text embedding space. LAMB incorporates a Cross-Modal Aligner that minimizes Cauchy-Schwarz divergence while maximizing mutual information, yielding tighter alignment between audio and text at both global and token levels. We further design a Two-Stream Adapter that extracts semantically enriched audio embeddings, thereby delivering richer information to the Cross-Modal Aligner. Finally, leveraging the aligned audio embeddings, a proposed Token Guide directly computes scores within the LLM text embedding space to steer the output logits of generated captions. Experimental results confirm that our framework strengthens the reasoning capabilities of the LLM decoder, achieving state-of-the-art performance on AudioCaps.
SEED: Speaker Embedding Enhancement Diffusion Model
May 22, 2025A primary challenge when deploying speaker recognition systems in real-world applications is performance degradation caused by environmental mismatch. We propose a diffusion-based method that takes speaker embeddings extracted from a pre-trained speaker recognition model and generates refined embeddings. For training, our approach progressively adds Gaussian noise to both clean and noisy speaker embeddings extracted from clean and noisy speech, respectively, via forward process of a diffusion model, and then reconstructs them to clean embeddings in the reverse process. While inferencing, all embeddings are regenerated via diffusion process. Our method needs neither speaker label nor any modification to the existing speaker recognition pipeline. Experiments on evaluation sets simulating environment mismatch scenarios show that our method can improve recognition accuracy by up to 19.6% over baseline models while retaining performance on conventional scenarios. We publish our code here https://github.com/kaistmm/seed-pytorch
Rethinking Session Variability: Leveraging Session Embeddings for Session Robustness in Speaker Verification
Sep 26, 2023

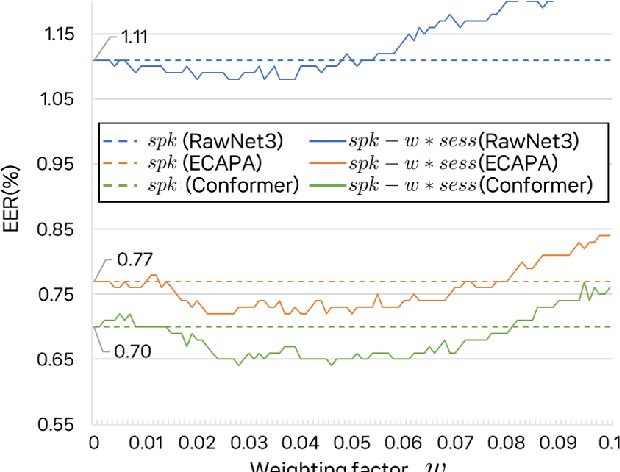
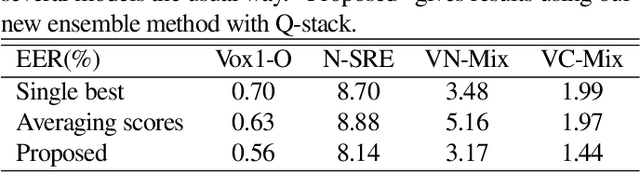
In the field of speaker verification, session or channel variability poses a significant challenge. While many contemporary methods aim to disentangle session information from speaker embeddings, we introduce a novel approach using an additional embedding to represent the session information. This is achieved by training an auxiliary network appended to the speaker embedding extractor which remains fixed in this training process. This results in two similarity scores: one for the speakers information and one for the session information. The latter score acts as a compensator for the former that might be skewed due to session variations. Our extensive experiments demonstrate that session information can be effectively compensated without retraining of the embedding extractor.