 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDAS: Efficient and Differentiable Architecture Search
Paper and Code
Dec 04, 2019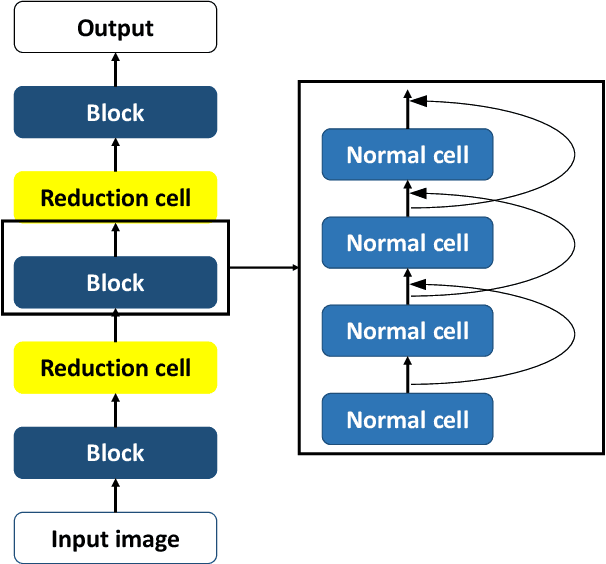

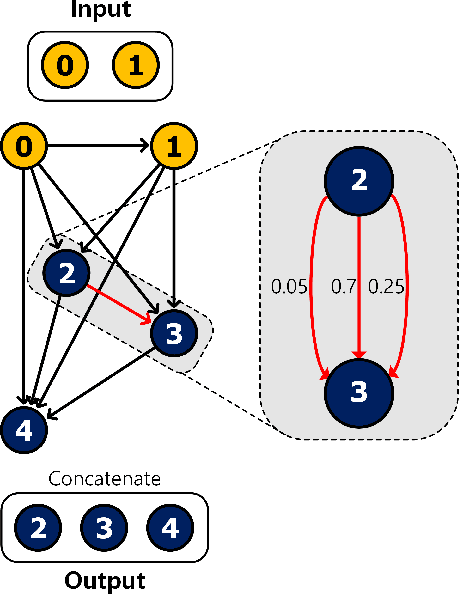
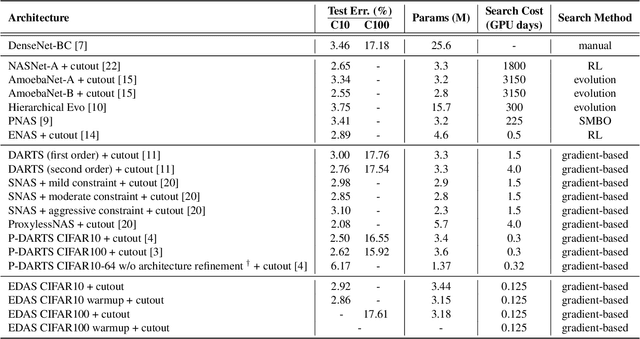
Transferrable neural architecture search can be viewed as a binary optimization problem where a single optimal path should be selected among candidate paths in each edge within the repeated cell block of the directed a cyclic graph form. Recently, the field of differentiable architecture search attempts to relax the search problem continuously using a one-shot network that combines all the candidate paths in search space. However, when the one-shot network is pruned to the model in the discrete architecture space by the derivation algorithm, performance is significantly degraded to an almost random estimator. To reduce the quantization error from the heavy use of relaxation, we only sample a single edge to relax the corresponding variable and clamp variables in the other edges to zero or one. By this method, there is no performance drop after pruning the one-shot network by derivation algorithm, due to the preservation of the discrete nature of optimization variables during the search. Furthermore, the minimization of relaxation degree allows searching in a deeper network to discover better performance with remarkable search cost reduction (0.125 GPU days) compared to previous methods. By adding several regularization methods that help explore within the search space, we could obtain the network with notable performances on CIFAR-10, CIFAR-100, and ImageNet.