 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Paper and Code
Nov 25, 2024

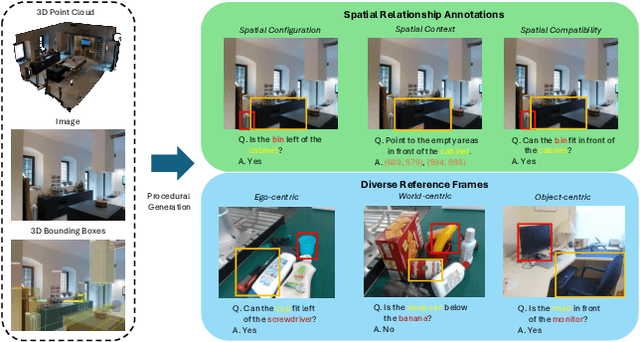

Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.