 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTLM Engineering Report: Dropout
Paper and Code
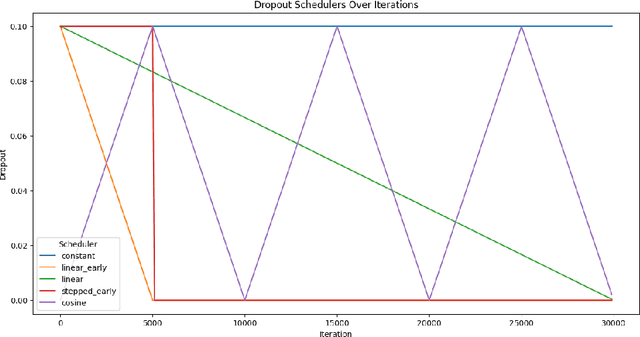
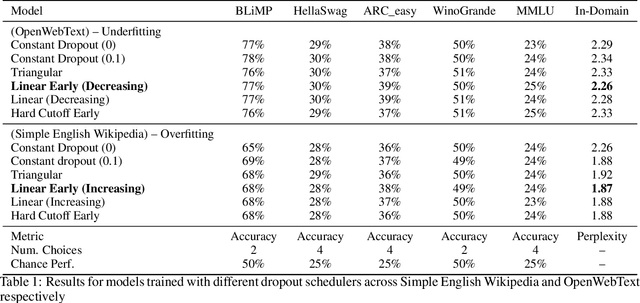
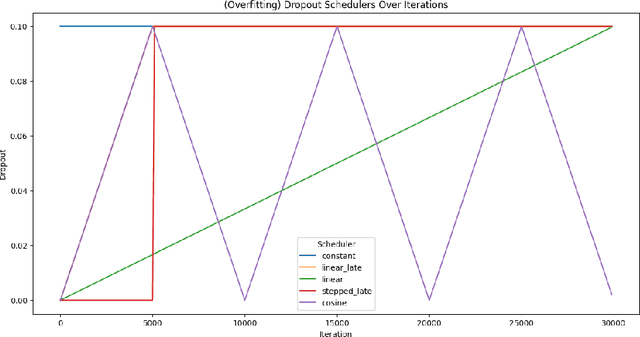
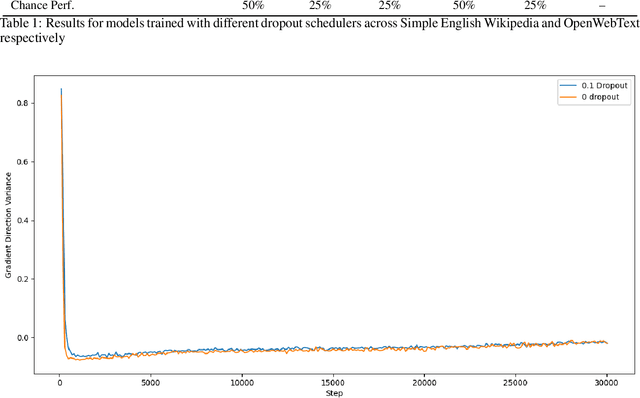
In this work we explore the relevance of dropout for modern language models, particularly in the context of models on the scale of <100M parameters. We explore it's relevance firstly in the regime of improving the sample efficiency of models given small, high quality datasets, and secondly in the regime of improving the quality of its fit on larger datasets where models may underfit. We find that concordant with conventional wisdom, dropout remains effective in the overfitting scenario, and that furthermore it may have some relevance for improving the fit of models even in the case of excess data, as suggested by previous research. In the process we find that the existing explanation for the mechanism behind this performance gain is not applicable in the case of language modelling.