 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer based time series prediction of the maximum power point for solar photovoltaic cells
Sep 24, 2024This paper proposes an improved deep learning based maximum power point tracking (MPPT) in solar photovoltaic cells considering various time series based environmental inputs. Generally, artificial neural network based MPPT algorithms use basic neural network architectures and inputs which do not represent the ambient conditions in a comprehensive manner. In this article, the ambient conditions of a location are represented through a comprehensive set of environmental features. Furthermore, the inclusion of time based features in the input data is considered to model cyclic patterns temporally within the atmospheric conditions leading to robust modeling of the MPPT algorithm. A transformer based deep learning architecture is trained as a time series prediction model using multidimensional time series input features. The model is trained on a dataset containing typical meteorological year data points of ambient weather conditions from 50 locations. The attention mechanism in the transformer modules allows the model to learn temporal patterns in the data efficiently. The proposed model achieves a 0.47% mean average percentage error of prediction on non zero operating voltage points in a test dataset consisting of data collected over a period of 200 consecutive hours resulting in the average power efficiency of 99.54% and peak power efficiency of 99.98%. The proposed model is validated through real time simulations. The proposed model performs power point tracking in a robust, dynamic, and nonlatent manner, over a wide range of atmospheric conditions.
* Published June 2022, in Energy Science and Engineering, Volume10, Issue9, Pages 3397-3410
Super Tiny Language Models
May 23, 2024The rapid advancement of large language models (LLMs) has led to significant improvements in natural language processing but also poses challenges due to their high computational and energy demands. This paper introduces a series of research efforts focused on Super Tiny Language Models (STLMs), which aim to deliver high performance with significantly reduced parameter counts. We explore innovative techniques such as byte-level tokenization with a pooling mechanism, weight tying, and efficient training strategies. These methods collectively reduce the parameter count by $90\%$ to $95\%$ compared to traditional models while maintaining competitive performance. This series of papers will explore into various subproblems, including tokenizer-free models, self-play based training, and alternative training objectives, targeting models with 10M, 50M, and 100M parameters. Our ultimate goal is to make high-performance language models more accessible and practical for a wide range of applications.
Exploring the Limitations of Graph Reasoning in Large Language Models
Feb 02, 2024
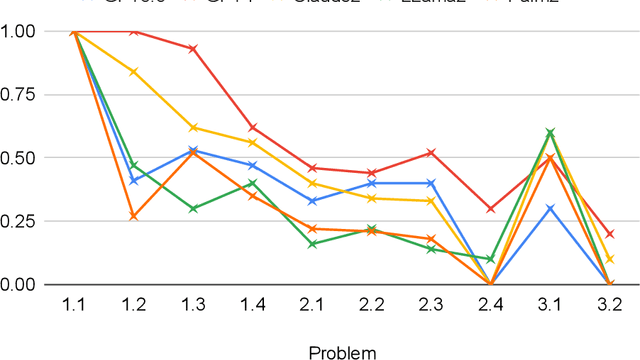
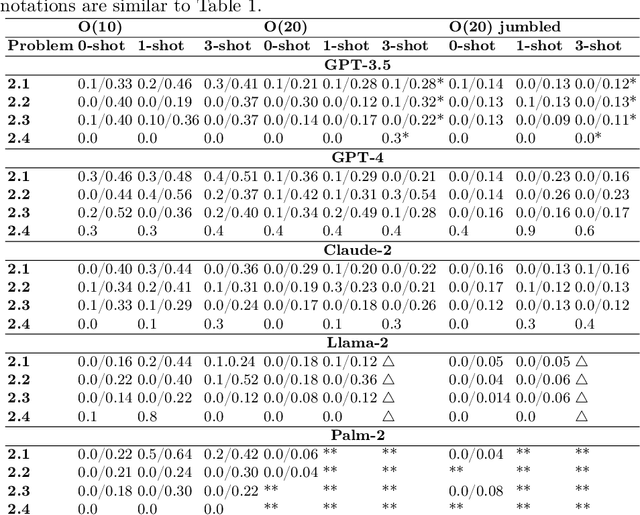
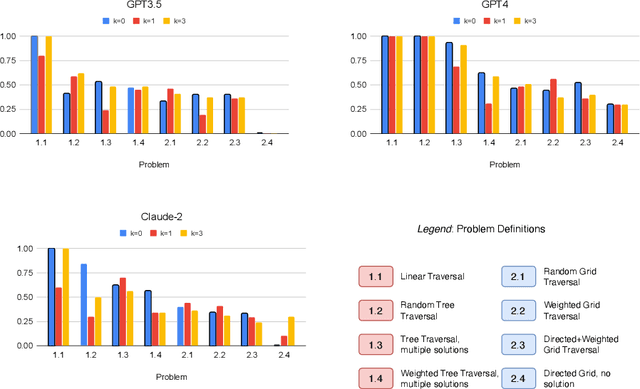
Pretrained Large Language Models have demonstrated various types of reasoning capabilities through language-based prompts alone. However, in this paper, we test the depth of graph reasoning for 5 different LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) through the problems of graph reasoning. In particular, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity. Further, we analyze the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases, and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we propose a new prompting technique specially designed for graph traversal tasks, known as PathCompare, which shows a notable increase in the performance of LLMs in comparison to standard prompting and CoT.
Advancing Perception in Artificial Intelligence through Principles of Cognitive Science
Oct 13, 2023



Although artificial intelligence (AI) has achieved many feats at a rapid pace, there still exist open problems and fundamental shortcomings related to performance and resource efficiency. Since AI researchers benchmark a significant proportion of performance standards through human intelligence, cognitive sciences-inspired AI is a promising domain of research. Studying cognitive science can provide a fresh perspective to building fundamental blocks in AI research, which can lead to improved performance and efficiency. In this review paper, we focus on the cognitive functions of perception, which is the process of taking signals from one's surroundings as input, and processing them to understand the environment. Particularly, we study and compare its various processes through the lens of both cognitive sciences and AI. Through this study, we review all current major theories from various sub-disciplines of cognitive science (specifically neuroscience, psychology and linguistics), and draw parallels with theories and techniques from current practices in AI. We, hence, present a detailed collection of methods in AI for researchers to build AI systems inspired by cognitive science. Further, through the process of reviewing the state of cognitive-inspired AI, we point out many gaps in the current state of AI (with respect to the performance of the human brain), and hence present potential directions for researchers to develop better perception systems in AI.
STUPD: A Synthetic Dataset for Spatial and Temporal Relation Reasoning
Sep 13, 2023



Understanding relations between objects is crucial for understanding the semantics of a visual scene. It is also an essential step in order to bridge visual and language models. However, current state-of-the-art computer vision models still lack the ability to perform spatial reasoning well. Existing datasets mostly cover a relatively small number of spatial relations, all of which are static relations that do not intrinsically involve motion. In this paper, we propose the Spatial and Temporal Understanding of Prepositions Dataset (STUPD) -- a large-scale video dataset for understanding static and dynamic spatial relationships derived from prepositions of the English language. The dataset contains 150K visual depictions (videos and images), consisting of 30 distinct spatial prepositional senses, in the form of object interaction simulations generated synthetically using Unity3D. In addition to spatial relations, we also propose 50K visual depictions across 10 temporal relations, consisting of videos depicting event/time-point interactions. To our knowledge, no dataset exists that represents temporal relations through visual settings. In this dataset, we also provide 3D information about object interactions such as frame-wise coordinates, and descriptions of the objects used. The goal of this synthetic dataset is to help models perform better in visual relationship detection in real-world settings. We demonstrate an increase in the performance of various models over 2 real-world datasets (ImageNet-VidVRD and Spatial Senses) when pretrained on the STUPD dataset, in comparison to other pretraining datasets.