 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limitations of Graph Reasoning in Large Language Models
Paper and Code

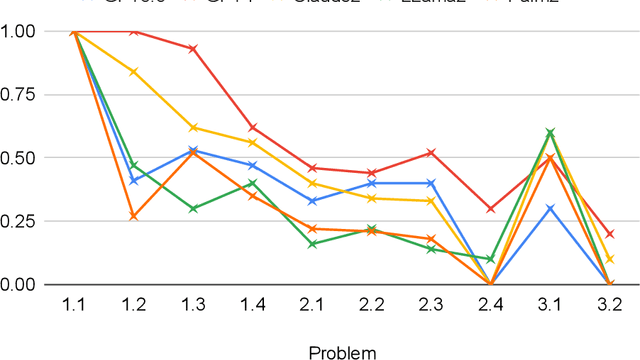
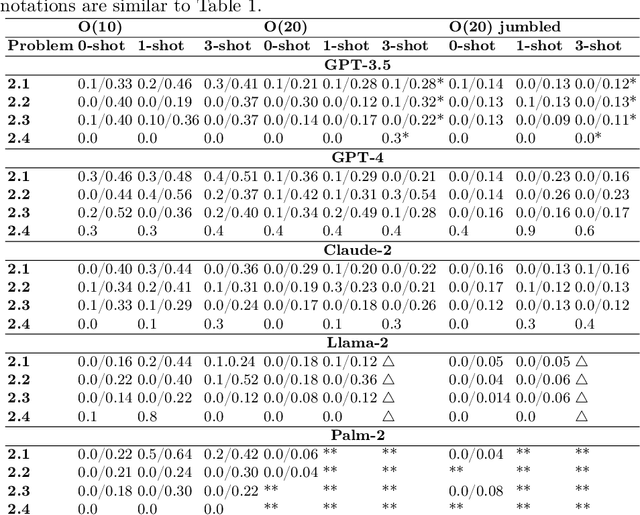
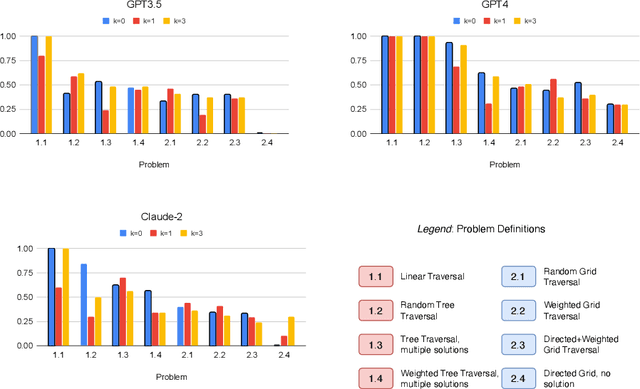
Pretrained Large Language Models have demonstrated various types of reasoning capabilities through language-based prompts alone. However, in this paper, we test the depth of graph reasoning for 5 different LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) through the problems of graph reasoning. In particular, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity. Further, we analyze the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases, and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we propose a new prompting technique specially designed for graph traversal tasks, known as PathCompare, which shows a notable increase in the performance of LLMs in comparison to standard prompting and CoT.