 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Task-oriented Grasp Generation
Feb 07, 2025



This paper presents a training-free pipeline for task-oriented grasp generation that combines pre-trained grasp generation models with vision-language models (VLMs). Unlike traditional approaches that focus solely on stable grasps, our method incorporates task-specific requirements by leveraging the semantic reasoning capabilities of VLMs. We evaluate five querying strategies, each utilizing different visual representations of candidate grasps, and demonstrate significant improvements over a baseline method in both grasp success and task compliance rates, with absolute gains of up to 36.9% in overall success rate. Our results underline the potential of VLMs to enhance task-oriented manipulation, providing insights for future research in robotic grasping and human-robot interaction.
Dipper: Diversity in Prompts for Producing Large Language Model Ensembles in Reasoning tasks
Dec 12, 2024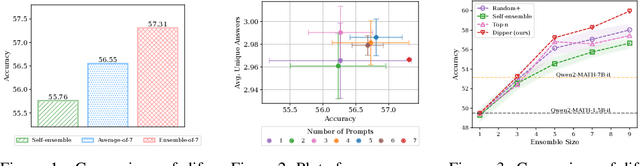



Large Language Models still encounter substantial challenges in reasoning tasks, especially for smaller models, which many users may be restricted to due to resource constraints (e.g. GPU memory restrictions). Inference-time methods to boost LLM performance, such as prompting methods to invoke certain reasoning pathways in responses, have been shown effective in past works, though they largely rely on sequential queries. The ensemble method, which consists of multiple constituent models running in parallel, is a promising approach to achieving better inference-time performance, especially given recent developments that enabled significant speed-ups in LLM batch inference. In this work, we propose a novel, training-free LLM ensemble framework where a single LLM model is fed an optimized, diverse set of prompts in parallel, effectively producing an ensemble at inference time to achieve performance improvement in reasoning tasks. We empirically demonstrate that our method leads to significant gains on math reasoning tasks, e.g., on MATH, where our ensemble consisting of a few small models (e.g., three Qwen2-MATH-1.5B-it models) can outperform a larger model (e.g., Qwen2-MATH-7B-it).