 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Orderings of Probability Vectors and Unsupervised Performance Estimation
Jun 16, 2023



Unsupervised performance estimation, or evaluating how well models perform on unlabeled data is a difficult task. Recently, a method was proposed by Garg et al. [2022] which performs much better than previous methods. Their method relies on having a score function, satisfying certain properties, to map probability vectors outputted by the classifier to the reals, but it is an open problem which score function is best. We explore this problem by first showing that their method fundamentally relies on the ordering induced by this score function. Thus, under monotone transformations of score functions, their method yields the same estimate. Next, we show that in the binary classification setting, nearly all common score functions - the $L^\infty$ norm; the $L^2$ norm; negative entropy; and the $L^2$, $L^1$, and Jensen-Shannon distances to the uniform vector - all induce the same ordering over probability vectors. However, this does not hold for higher dimensional settings. We conduct numerous experiments on well-known NLP data sets and rigorously explore the performance of different score functions. We conclude that the $L^\infty$ norm is the most appropriate.
A Dynamic Strategy Coach for Effective Negotiation
Sep 30, 2019


Negotiation is a complex activity involving strategic reasoning, persuasion, and psychology. An average person is often far from an expert in negotiation. Our goal is to assist humans to become better negotiators through a machine-in-the-loop approach that combines machine's advantage at data-driven decision-making and human's language generation ability. We consider a bargaining scenario where a seller and a buyer negotiate the price of an item for sale through a text-based dialog. Our negotiation coach monitors messages between them and recommends tactics in real time to the seller to get a better deal (e.g., "reject the proposal and propose a price", "talk about your personal experience with the product"). The best strategy and tactics largely depend on the context (e.g., the current price, the buyer's attitude). Therefore, we first identify a set of negotiation tactics, then learn to predict the best strategy and tactics in a given dialog context from a set of human-human bargaining dialogs. Evaluation on human-human dialogs shows that our coach increases the profits of the seller by almost 60%.
Augmenting Non-Collaborative Dialog Systems with Explicit Semantic and Strategic Dialog History
Sep 30, 2019
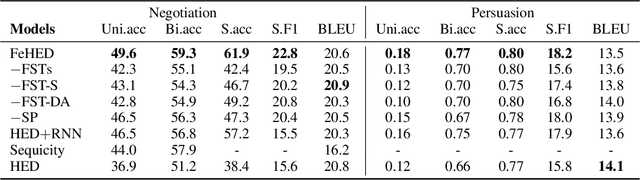

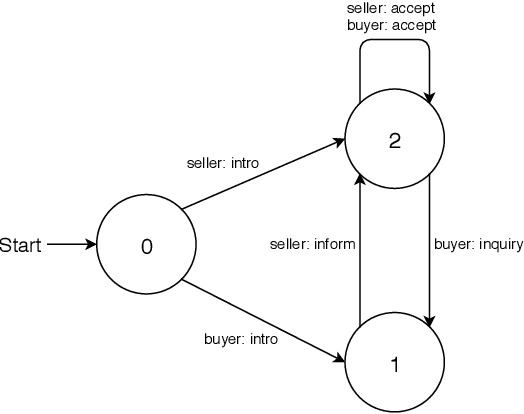
We study non-collaborative dialogs, where two agents have a conflict of interest but must strategically communicate to reach an agreement (e.g., negotiation). This setting poses new challenges for modeling dialog history because the dialog's outcome relies not only on the semantic intent, but also on tactics that convey the intent. We propose to model both semantic and tactic history using finite state transducers (FSTs). Unlike RNN, FSTs can explicitly represent dialog history through all the states traversed, facilitating interpretability of dialog structure. We train FSTs on a set of strategies and tactics used in negotiation dialogs. The trained FSTs show plausible tactic structure and can be generalized to other non-collaborative domains (e.g., persuasion). We evaluate the FSTs by incorporating them in an automated negotiating system that attempts to sell products and a persuasion system that persuades people to donate to a charity. Experiments show that explicitly modeling both semantic and tactic history is an effective way to improve both dialog policy planning and generation performance.