 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of the Effectiveness of an Ensemble of Stand-alone Sentiment Detection Tools for Software Engineering Datasets
Nov 04, 2021


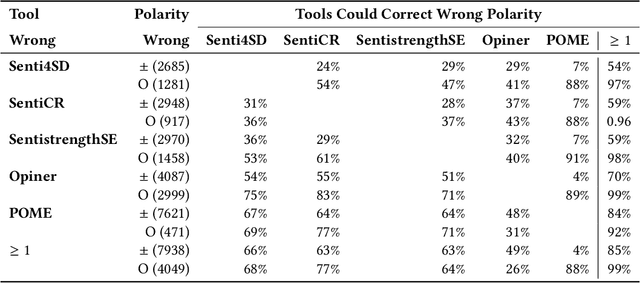
Sentiment analysis in software engineering (SE) has shown promise to analyze and support diverse development activities. We report the results of an empirical study that we conducted to determine the feasibility of developing an ensemble engine by combining the polarity labels of stand-alone SE-specific sentiment detectors. Our study has two phases. In the first phase, we pick five SE-specific sentiment detection tools from two recently published papers by Lin et al. [31, 32], who first reported negative results with standalone sentiment detectors and then proposed an improved SE-specific sentiment detector, POME [31]. We report the study results on 17,581 units (sentences/documents) coming from six currently available sentiment benchmarks for SE. We find that the existing tools can be complementary to each other in 85-95% of the cases, i.e., one is wrong, but another is right. However, a majority voting-based ensemble of those tools fails to improve the accuracy of sentiment detection. We develop Sentisead, a supervised tool by combining the polarity labels and bag of words as features. Sentisead improves the performance (F1-score) of the individual tools by 4% (over Senti4SD [5]) - 100% (over POME [31]). In a second phase, we compare and improve Sentisead infrastructure using Pre-trained Transformer Models (PTMs). We find that a Sentisead infrastructure with RoBERTa as the ensemble of the five stand-alone rule-based and shallow learning SE-specific tools from Lin et al. [31, 32] offers the best F1-score of 0.805 across the six datasets, while a stand-alone RoBERTa shows an F1-score of 0.801.
Studying Software Engineering Patterns for Designing Machine Learning Systems
Oct 11, 2019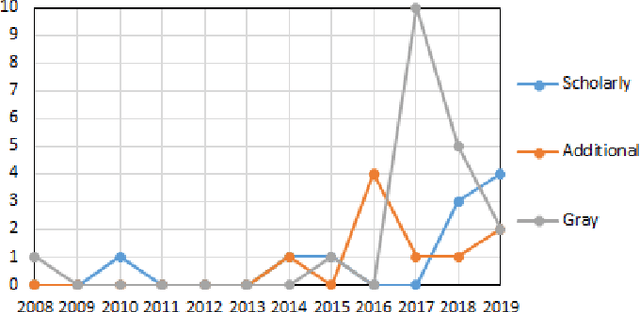
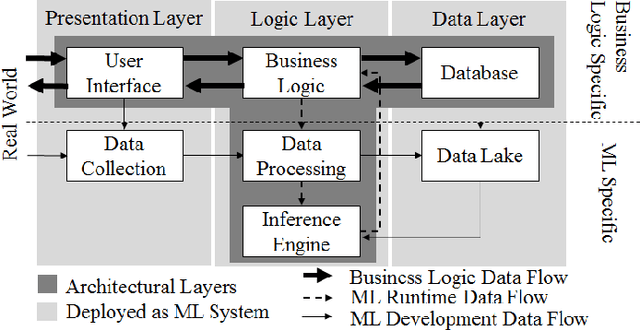

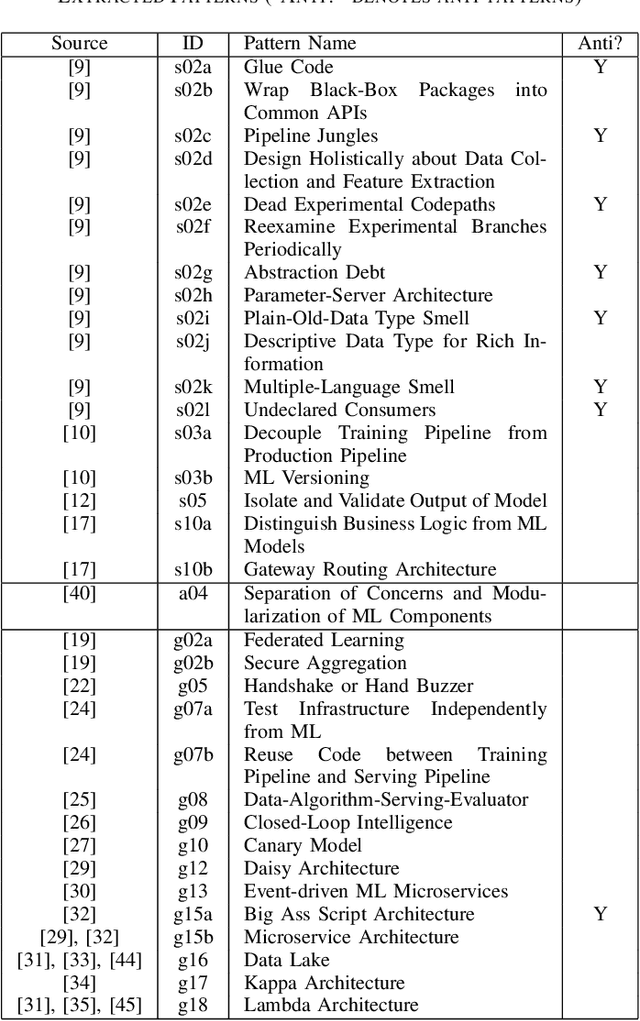
Machine-learning (ML) techniques have become popular in the recent years. ML techniques rely on mathematics and on software engineering. Researchers and practitioners studying best practices for designing ML application systems and software to address the software complexity and quality of ML techniques. Such design practices are often formalized as architecture patterns and design patterns by encapsulating reusable solutions to commonly occurring problems within given contexts. However, to the best of our knowledge, there has been no work collecting, classifying, and discussing these software-engineering (SE) design patterns for ML techniques systematically. Thus, we set out to collect good/bad SE design patterns for ML techniques to provide developers with a comprehensive and ordered classification of such patterns. We report here preliminary results of a systematic-literature review (SLR) of good/bad design patterns for ML.