 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Driven Universal Model for Organ Segmentation and Tumor Detection
Jan 06, 2023



An increasing number of public datasets have shown a marked clinical impact on assessing anatomical structures. However, each of the datasets is small, partially labeled, and rarely investigates severe tumor subjects. Moreover, current models are limited to segmenting specific organs/tumors, which can not be extended to novel domains and classes. To tackle these limitations, we introduce embedding learned from Contrastive Language-Image Pre-training (CLIP) to segmentation models, dubbed the CLIP-Driven Universal Model. The Universal Model can better segment 25 organs and 6 types of tumors by exploiting the semantic relationship between abdominal structures. The model is developed from an assembly of 14 datasets with 3,410 CT scans and evaluated on 6,162 external CT scans from 3 datasets. We achieve the state-of-the-art results on Beyond The Cranial Vault (BTCV). Compared with dataset-specific models, the Universal Model is computationally more efficient (6x faster), generalizes better to CT scans from varying sites, and shows stronger transfer learning performance on novel tasks. The design of CLIP embedding enables the Universal Model to be easily extended to new classes without catastrophically forgetting the previously learned classes.
LUMix: Improving Mixup by Better Modelling Label Uncertainty
Nov 29, 2022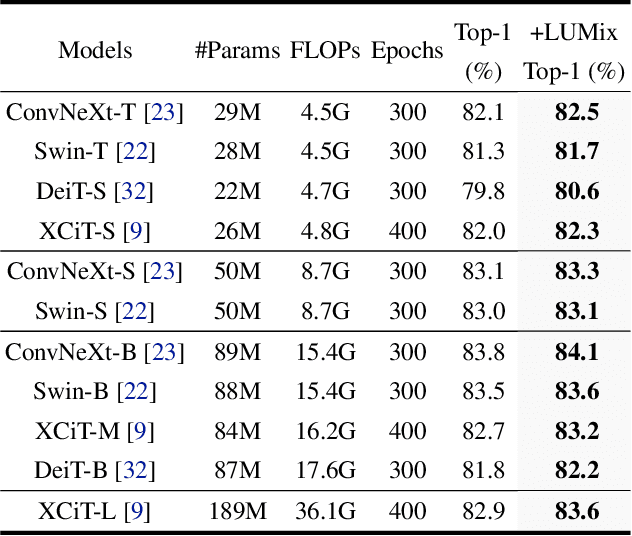



Modern deep networks can be better generalized when trained with noisy samples and regularization techniques. Mixup and CutMix have been proven to be effective for data augmentation to help avoid overfitting. Previous Mixup-based methods linearly combine images and labels to generate additional training data. However, this is problematic if the object does not occupy the whole image as we demonstrate in Figure 1. Correctly assigning the label weights is hard even for human beings and there is no clear criterion to measure it. To tackle this problem, in this paper, we propose LUMix, which models such uncertainty by adding label perturbation during training. LUMix is simple as it can be implemented in just a few lines of code and can be universally applied to any deep networks \eg CNNs and Vision Transformers, with minimal computational cost. Extensive experiments show that our LUMix can consistently boost the performance for networks with a wide range of diversity and capacity on ImageNet, \eg $+0.7\%$ for a small model DeiT-S and $+0.6\%$ for a large variant XCiT-L. We also demonstrate that LUMix can lead to better robustness when evaluated on ImageNet-O and ImageNet-A. The source code can be found \href{https://github.com/kevin-ssy/LUMix}{here}
Synthetic Tumors Make AI Segment Tumors Better
Oct 26, 2022

We develop a novel strategy to generate synthetic tumors. Unlike existing works, the tumors generated by our strategy have two intriguing advantages: (1) realistic in shape and texture, which even medical professionals can confuse with real tumors; (2) effective for AI model training, which can perform liver tumor segmentation similarly to a model trained on real tumors - this result is unprecedented because no existing work, using synthetic tumors only, has thus far reached a similar or even close performance to the model trained on real tumors. This result also implies that manual efforts for developing per-voxel annotation of tumors (which took years to create) can be considerably reduced for training AI models in the future. Moreover, our synthetic tumors have the potential to improve the success rate of small tumor detection by automatically generating enormous examples of small (or tiny) synthetic tumors.
PartImageNet: A Large, High-Quality Dataset of Parts
Dec 02, 2021
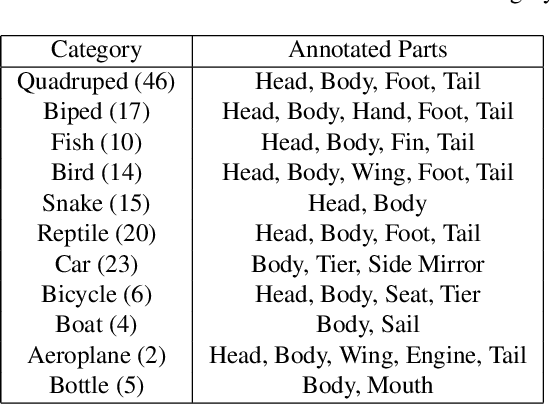

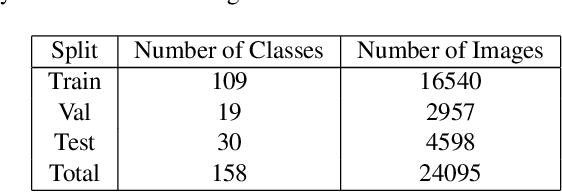
A part-based object understanding facilitates efficient compositional learning and knowledge transfer, robustness to occlusion, and has the potential to increase the performance on general recognition and localization tasks. However, research on part-based models is hindered due to the lack of datasets with part annotations, which is caused by the extreme difficulty and high cost of annotating object parts in images. In this paper, we propose PartImageNet, a large, high-quality dataset with part segmentation annotations. It consists of 158 classes from ImageNet with approximately 24000 images. PartImageNet is unique because it offers part-level annotations on a general set of classes with non-rigid, articulated objects, while having an order of magnitude larger size compared to existing datasets. It can be utilized in multiple vision tasks including but not limited to: Part Discovery, Semantic Segmentation, Few-shot Learning. Comprehensive experiments are conducted to set up a set of baselines on PartImageNet and we find that existing works on part discovery can not always produce satisfactory results during complex variations. The exploit of parts on downstream tasks also remains insufficient. We believe that our PartImageNet will greatly facilitate the research on part-based models and their applications. The dataset and scripts will soon be released at https://github.com/TACJu/PartImageNet.
TransMix: Attend to Mix for Vision Transformers
Nov 18, 2021
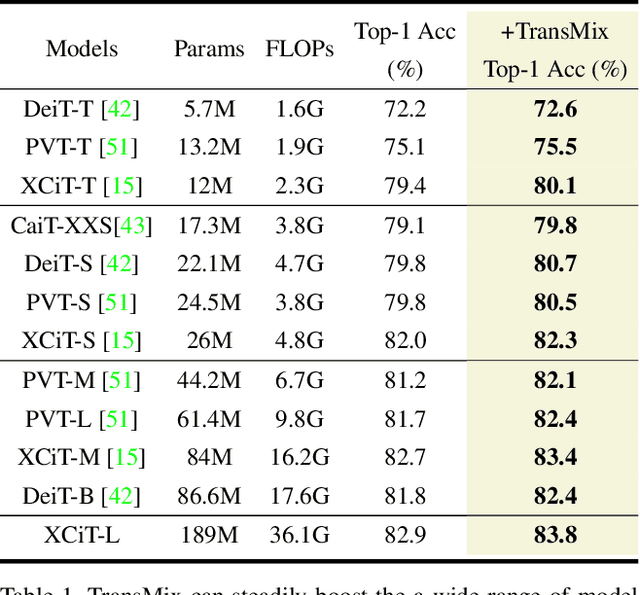
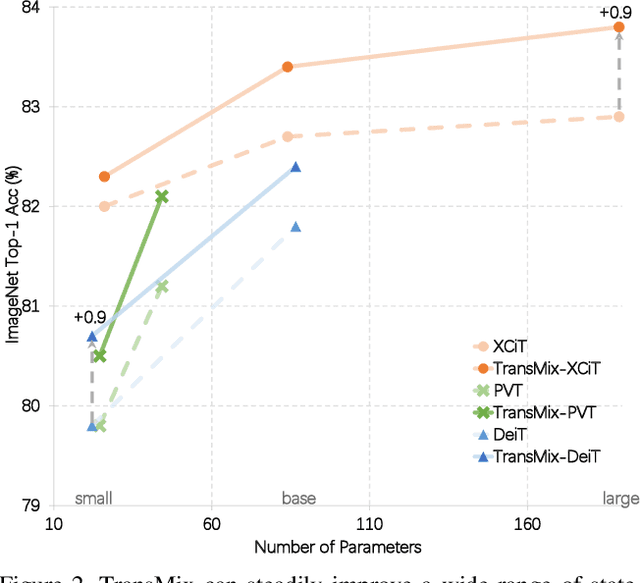

Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks. Code will be made publicly available at https://github.com/Beckschen/TransMix.
TransFG: A Transformer Architecture for Fine-grained Recognition
Mar 28, 2021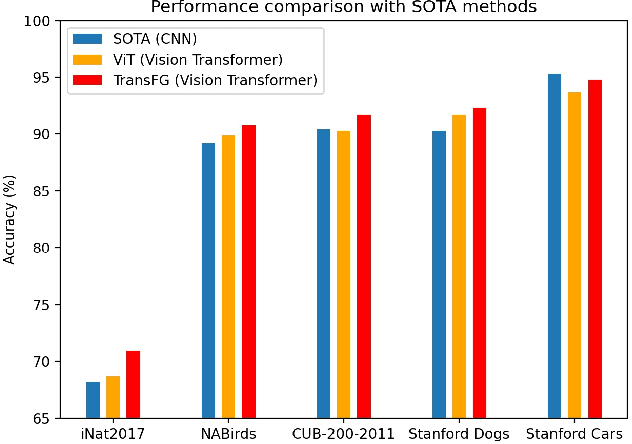
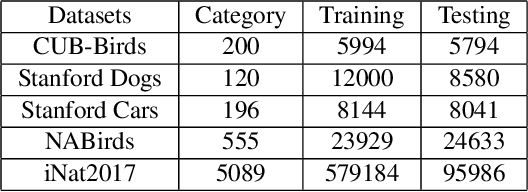
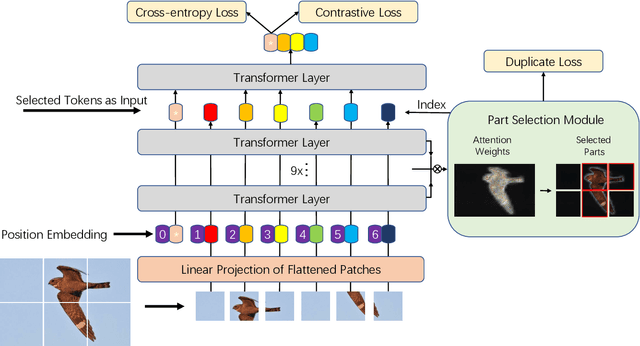
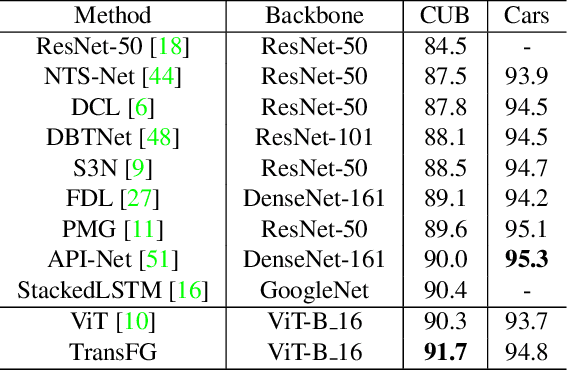
Fine-grained visual classification (FGVC) which aims at recognizing objects from subcategories is a very challenging task due to the inherently subtle inter-class differences. Recent works mainly tackle this problem by focusing on how to locate the most discriminative image regions and rely on them to improve the capability of networks to capture subtle variances. Most of these works achieve this by re-using the backbone network to extract features of selected regions. However, this strategy inevitably complicates the pipeline and pushes the proposed regions to contain most parts of the objects. Recently, vision transformer (ViT) shows its strong performance in the traditional classification task. The self-attention mechanism of the transformer links every patch token to the classification token. The strength of the attention link can be intuitively considered as an indicator of the importance of tokens. In this work, we propose a novel transformer-based framework TransFG where we integrate all raw attention weights of the transformer into an attention map for guiding the network to effectively and accurately select discriminative image patches and compute their relations. A contrastive loss is applied to further enlarge the distance between feature representations of similar sub-classes. We demonstrate the value of TransFG by conducting experiments on five popular fine-grained benchmarks: CUB-200-2011, Stanford Cars, Stanford Dogs, NABirds and iNat2017 where we achieve state-of-the-art performance. Qualitative results are presented for better understanding of our model. Code is available at https://github.com/TACJu/TransFG.