 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization with Large Language Models
Apr 15, 2025The exponential increase in video content poses significant challenges in terms of efficient navigation, search, and retrieval, thus requiring advanced video summarization techniques. Existing video summarization methods, which heavily rely on visual features and temporal dynamics, often fail to capture the semantics of video content, resulting in incomplete or incoherent summaries. To tackle the challenge, we propose a new video summarization framework that leverages the capabilities of recent Large Language Models (LLMs), expecting that the knowledge learned from massive data enables LLMs to evaluate video frames in a manner that better aligns with diverse semantics and human judgments, effectively addressing the inherent subjectivity in defining keyframes. Our method, dubbed LLM-based Video Summarization (LLMVS), translates video frames into a sequence of captions using a Muti-modal Large Language Model (M-LLM) and then assesses the importance of each frame using an LLM, based on the captions in its local context. These local importance scores are refined through a global attention mechanism in the entire context of video captions, ensuring that our summaries effectively reflect both the details and the overarching narrative. Our experimental results demonstrate the superiority of the proposed method over existing ones in standard benchmarks, highlighting the potential of LLMs in the processing of multimedia content.
ActFusion: a Unified Diffusion Model for Action Segmentation and Anticipation
Dec 05, 2024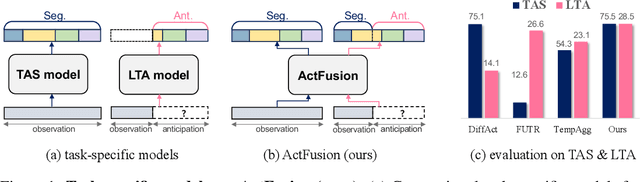
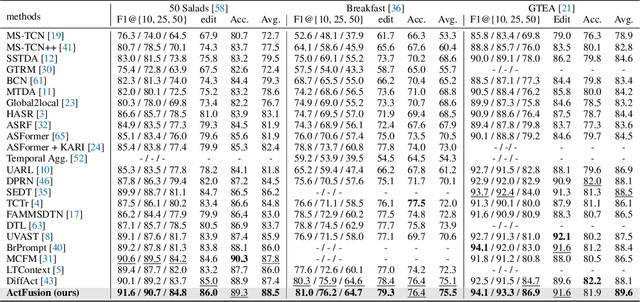
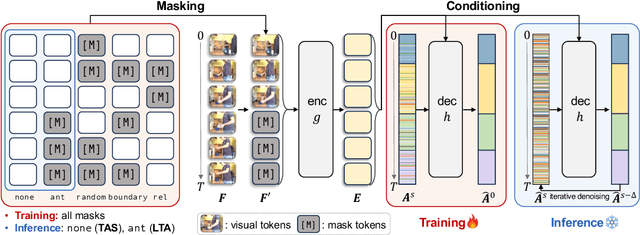
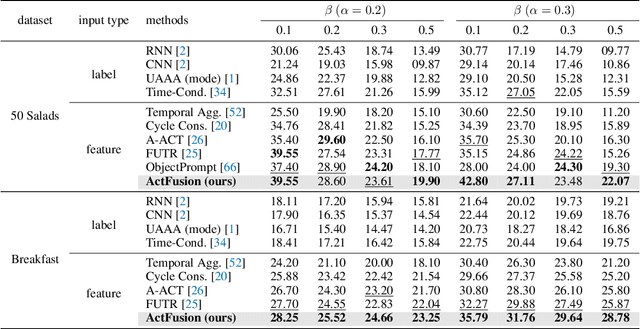
Temporal action segmentation and long-term action anticipation are two popular vision tasks for the temporal analysis of actions in videos. Despite apparent relevance and potential complementarity, these two problems have been investigated as separate and distinct tasks. In this work, we tackle these two problems, action segmentation and action anticipation, jointly using a unified diffusion model dubbed ActFusion. The key idea to unification is to train the model to effectively handle both visible and invisible parts of the sequence in an integrated manner; the visible part is for temporal segmentation, and the invisible part is for future anticipation. To this end, we introduce a new anticipative masking strategy during training in which a late part of the video frames is masked as invisible, and learnable tokens replace these frames to learn to predict the invisible future. Experimental results demonstrate the bi-directional benefits between action segmentation and anticipation. ActFusion achieves the state-of-the-art performance across the standard benchmarks of 50 Salads, Breakfast, and GTEA, outperforming task-specific models in both of the two tasks with a single unified model through joint learning.
Activity Grammars for Temporal Action Segmentation
Dec 07, 2023



Sequence prediction on temporal data requires the ability to understand compositional structures of multi-level semantics beyond individual and contextual properties. The task of temporal action segmentation, which aims at translating an untrimmed activity video into a sequence of action segments, remains challenging for this reason. This paper addresses the problem by introducing an effective activity grammar to guide neural predictions for temporal action segmentation. We propose a novel grammar induction algorithm that extracts a powerful context-free grammar from action sequence data. We also develop an efficient generalized parser that transforms frame-level probability distributions into a reliable sequence of actions according to the induced grammar with recursive rules. Our approach can be combined with any neural network for temporal action segmentation to enhance the sequence prediction and discover its compositional structure. Experimental results demonstrate that our method significantly improves temporal action segmentation in terms of both performance and interpretability on two standard benchmarks, Breakfast and 50 Salads.
Future Transformer for Long-term Action Anticipation
May 27, 2022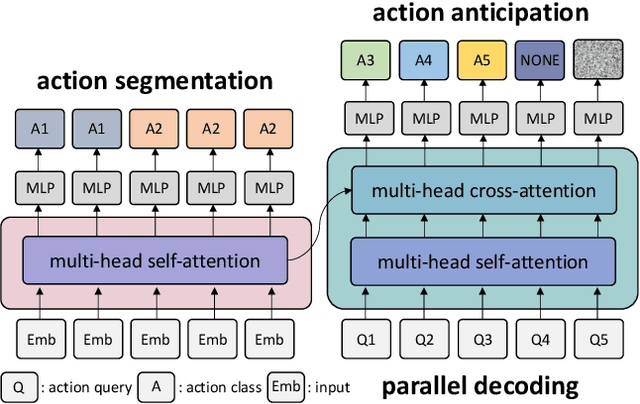
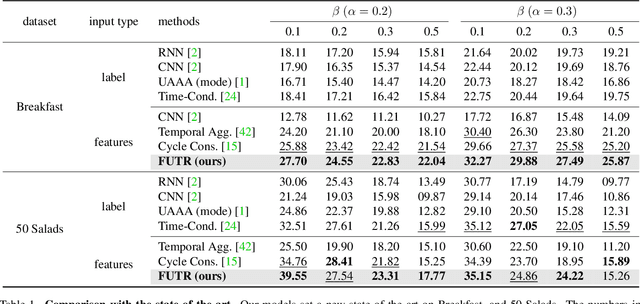
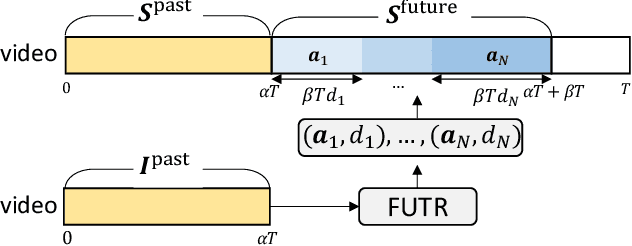
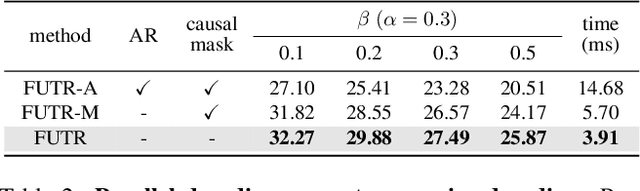
The task of predicting future actions from a video is crucial for a real-world agent interacting with others. When anticipating actions in the distant future, we humans typically consider long-term relations over the whole sequence of actions, i.e., not only observed actions in the past but also potential actions in the future. In a similar spirit, we propose an end-to-end attention model for action anticipation, dubbed Future Transformer (FUTR), that leverages global attention over all input frames and output tokens to predict a minutes-long sequence of future actions. Unlike the previous autoregressive models, the proposed method learns to predict the whole sequence of future actions in parallel decoding, enabling more accurate and fast inference for long-term anticipation. We evaluate our method on two standard benchmarks for long-term action anticipation, Breakfast and 50 Salads, achieving state-of-the-art results.