 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Transformer for Long-term Action Anticipation
Paper and Code
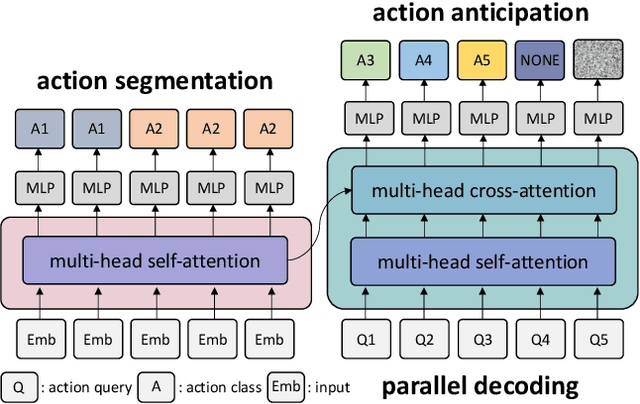
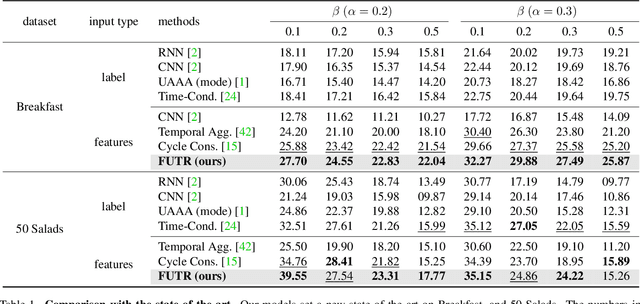
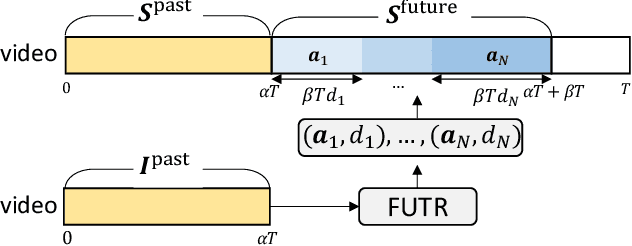
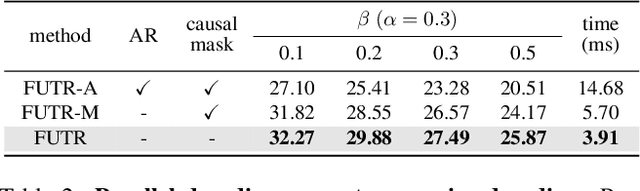
The task of predicting future actions from a video is crucial for a real-world agent interacting with others. When anticipating actions in the distant future, we humans typically consider long-term relations over the whole sequence of actions, i.e., not only observed actions in the past but also potential actions in the future. In a similar spirit, we propose an end-to-end attention model for action anticipation, dubbed Future Transformer (FUTR), that leverages global attention over all input frames and output tokens to predict a minutes-long sequence of future actions. Unlike the previous autoregressive models, the proposed method learns to predict the whole sequence of future actions in parallel decoding, enabling more accurate and fast inference for long-term anticipation. We evaluate our method on two standard benchmarks for long-term action anticipation, Breakfast and 50 Salads, achieving state-of-the-art results.