 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Global-Instance Prompt Tuning for Continual Test-time Adaptation in Medical Image Segmentation
Feb 05, 2026Distribution shift is a common challenge in medical images obtained from different clinical centers, significantly hindering the deployment of pre-trained semantic segmentation models in real-world applications across multiple domains. Continual Test-Time Adaptation(CTTA) has emerged as a promising approach to address cross-domain shifts during continually evolving target domains. Most existing CTTA methods rely on incrementally updating model parameters, which inevitably suffer from error accumulation and catastrophic forgetting, especially in long-term adaptation. Recent prompt-tuning-based works have shown potential to mitigate the two issues above by updating only visual prompts. While these approaches have demonstrated promising performance, several limitations remain:1)lacking multi-scale prompt diversity, 2)inadequate incorporation of instance-specific knowledge, and 3)risk of privacy leakage. To overcome these limitations, we propose Multi-scale Global-Instance Prompt Tuning(MGIPT), to enhance scale diversity of prompts and capture both global- and instance-level knowledge for robust CTTA. Specifically, MGIPT consists of an Adaptive-scale Instance Prompt(AIP) and a Multi-scale Global-level Prompt(MGP). AIP dynamically learns lightweight and instance-specific prompts to mitigate error accumulation with adaptive optimal-scale selection mechanism. MGP captures domain-level knowledge across different scales to ensure robust adaptation with anti-forgetting capabilities. These complementary components are combined through a weighted ensemble approach, enabling effective dual-level adaptation that integrates both global and local information. Extensive experiments on medical image segmentation benchmarks demonstrate that our MGIPT outperforms state-of-the-art methods, achieving robust adaptation across continually changing target domains.
Mamba-3D as Masked Autoencoders for Accurate and Data-Efficient Analysis of Medical Ultrasound Videos
Mar 26, 2025Ultrasound videos are an important form of clinical imaging data, and deep learning-based automated analysis can improve diagnostic accuracy and clinical efficiency. However, the scarcity of labeled data and the inherent challenges of video analysis have impeded the advancement of related methods. In this work, we introduce E-ViM$^3$, a data-efficient Vision Mamba network that preserves the 3D structure of video data, enhancing long-range dependencies and inductive biases to better model space-time correlations. With our design of Enclosure Global Tokens (EGT), the model captures and aggregates global features more effectively than competing methods. To further improve data efficiency, we employ masked video modeling for self-supervised pre-training, with the proposed Spatial-Temporal Chained (STC) masking strategy designed to adapt to various video scenarios. Experiments demonstrate that E-ViM$^3$ performs as the state-of-the-art in two high-level semantic analysis tasks across four datasets of varying sizes: EchoNet-Dynamic, CAMUS, MICCAI-BUV, and WHBUS. Furthermore, our model achieves competitive performance with limited labels, highlighting its potential impact on real-world clinical applications.
XNet v2: Fewer Limitations, Better Results and Greater Universality
Sep 02, 2024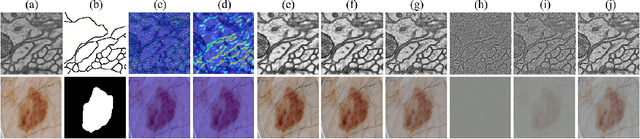
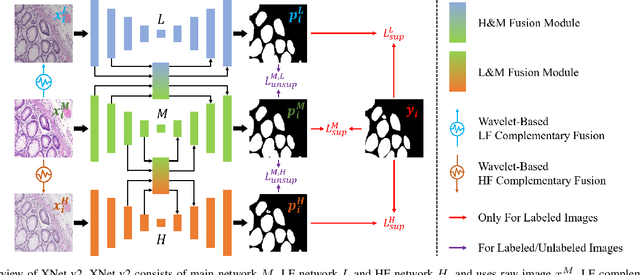
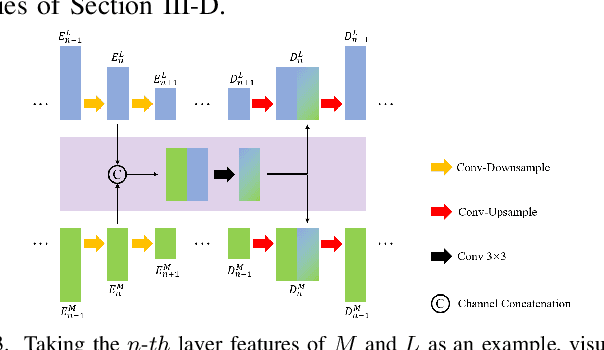
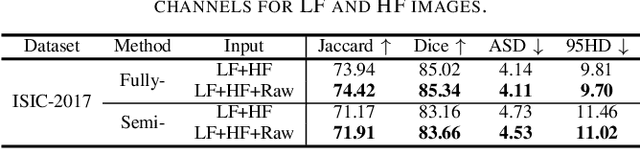
XNet introduces a wavelet-based X-shaped unified architecture for fully- and semi-supervised biomedical segmentation. So far, however, XNet still faces the limitations, including performance degradation when images lack high-frequency (HF) information, underutilization of raw images and insufficient fusion. To address these issues, we propose XNet v2, a low- and high-frequency complementary model. XNet v2 performs wavelet-based image-level complementary fusion, using fusion results along with raw images inputs three different sub-networks to construct consistency loss. Furthermore, we introduce a feature-level fusion module to enhance the transfer of low-frequency (LF) information and HF information. XNet v2 achieves state-of-the-art in semi-supervised segmentation while maintaining competitve results in fully-supervised learning. More importantly, XNet v2 excels in scenarios where XNet fails. Compared to XNet, XNet v2 exhibits fewer limitations, better results and greater universality. Extensive experiments on three 2D and two 3D datasets demonstrate the effectiveness of XNet v2. Code is available at https://github.com/Yanfeng-Zhou/XNetv2 .
Representing Topological Self-Similarity Using Fractal Feature Maps for Accurate Segmentation of Tubular Structures
Jul 20, 2024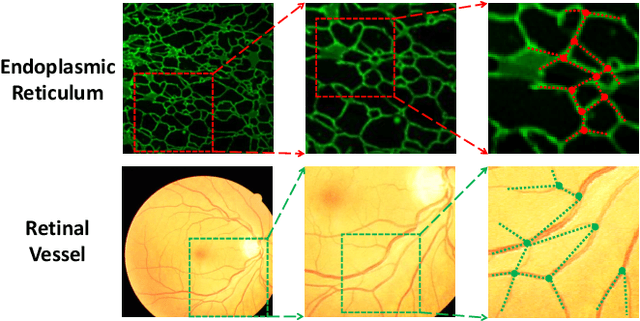
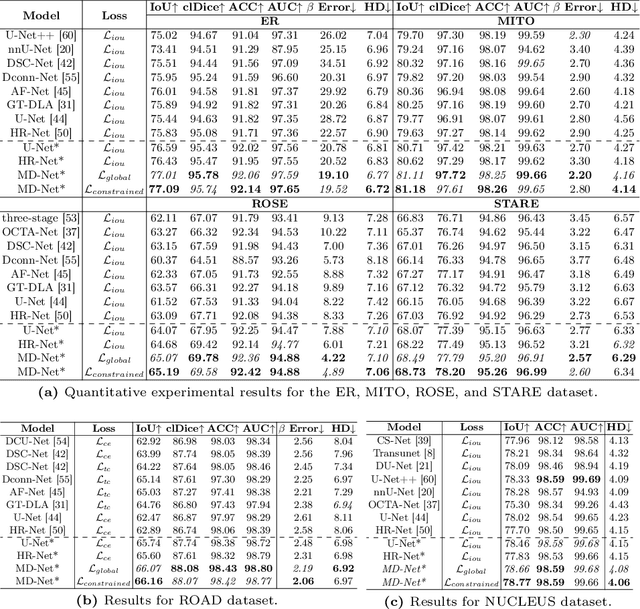
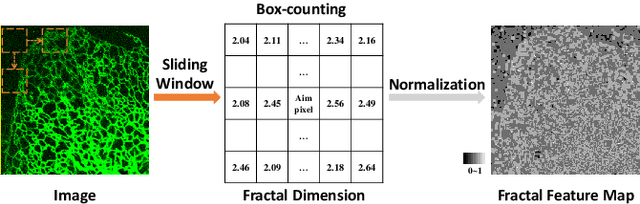
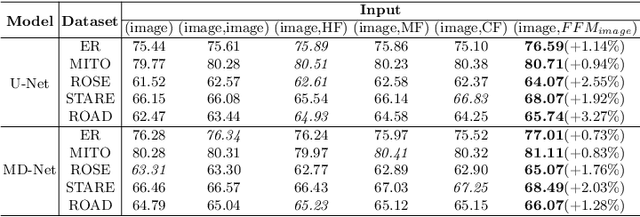
Accurate segmentation of long and thin tubular structures is required in a wide variety of areas such as biology, medicine, and remote sensing. The complex topology and geometry of such structures often pose significant technical challenges. A fundamental property of such structures is their topological self-similarity, which can be quantified by fractal features such as fractal dimension (FD). In this study, we incorporate fractal features into a deep learning model by extending FD to the pixel-level using a sliding window technique. The resulting fractal feature maps (FFMs) are then incorporated as additional input to the model and additional weight in the loss function to enhance segmentation performance by utilizing the topological self-similarity. Moreover, we extend the U-Net architecture by incorporating an edge decoder and a skeleton decoder to improve boundary accuracy and skeletal continuity of segmentation, respectively. Extensive experiments on five tubular structure datasets validate the effectiveness and robustness of our approach. Furthermore, the integration of FFMs with other popular segmentation models such as HR-Net also yields performance enhancement, suggesting FFM can be incorporated as a plug-in module with different model architectures. Code and data are openly accessible at https://github.com/cbmi-group/FFM-Multi-Decoder-Network.
Robust Source-Free Domain Adaptation for Fundus Image Segmentation
Oct 25, 2023Unsupervised Domain Adaptation (UDA) is a learning technique that transfers knowledge learned in the source domain from labelled training data to the target domain with only unlabelled data. It is of significant importance to medical image segmentation because of the usual lack of labelled training data. Although extensive efforts have been made to optimize UDA techniques to improve the accuracy of segmentation models in the target domain, few studies have addressed the robustness of these models under UDA. In this study, we propose a two-stage training strategy for robust domain adaptation. In the source training stage, we utilize adversarial sample augmentation to enhance the robustness and generalization capability of the source model. And in the target training stage, we propose a novel robust pseudo-label and pseudo-boundary (PLPB) method, which effectively utilizes unlabeled target data to generate pseudo labels and pseudo boundaries that enable model self-adaptation without requiring source data. Extensive experimental results on cross-domain fundus image segmentation confirm the effectiveness and versatility of our method. Source code of this study is openly accessible at https://github.com/LinGrayy/PLPB.