 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVim-F: Visual State Space Model Benefiting from Learning in the Frequency Domain
Paper and Code
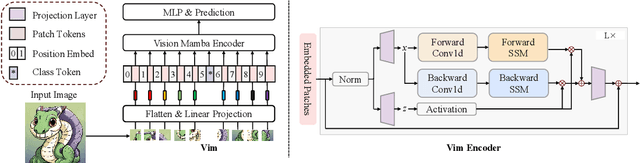

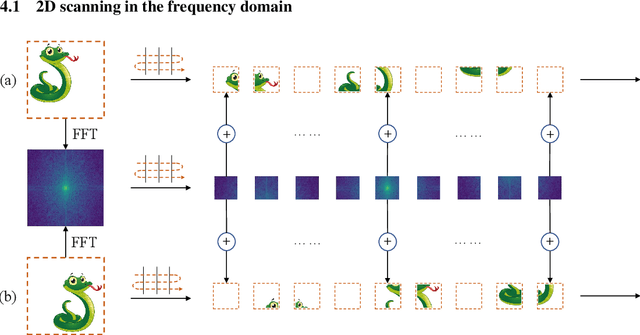
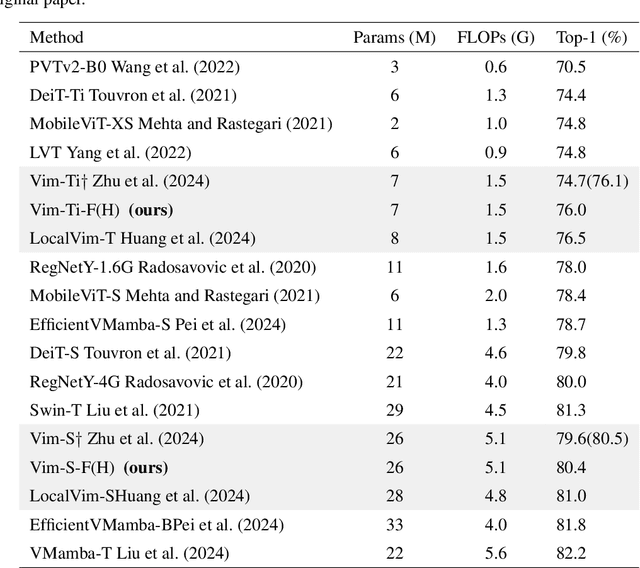
In recent years, State Space Models (SSMs) with efficient hardware-aware designs, known as the Mamba deep learning models, have made significant progress in modeling long sequences such as language understanding. Therefore, building efficient and general-purpose visual backbones based on SSMs is a promising direction. Compared to traditional convolutional neural networks (CNNs) and Vision Transformers (ViTs), the performance of Vision Mamba (ViM) methods is not yet fully competitive. To enable SSMs to process image data, ViMs typically flatten 2D images into 1D sequences, inevitably ignoring some 2D local dependencies, thereby weakening the model's ability to interpret spatial relationships from a global perspective. We use Fast Fourier Transform (FFT) to obtain the spectrum of the feature map and add it to the original feature map, enabling ViM to model a unified visual representation in both frequency and spatial domains. The introduction of frequency domain information enables ViM to have a global receptive field during scanning. We propose a novel model called Vim-F, which employs pure Mamba encoders and scans in both the frequency and spatial domains. Moreover, we question the necessity of position embedding in ViM and remove it accordingly in Vim-F, which helps to fully utilize the efficient long-sequence modeling capability of ViM. Finally, we redesign a patch embedding for Vim-F, leveraging a convolutional stem to capture more local correlations, further improving the performance of Vim-F. Code is available at: \url{https://github.com/yws-wxs/Vim-F}.