 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Robust Spiking Neural Networks with ViewPoint Transform and SpatioTemporal Stretching
Mar 14, 2023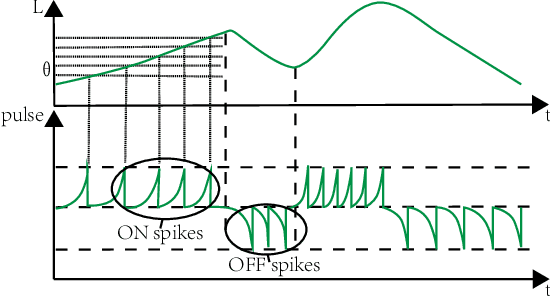
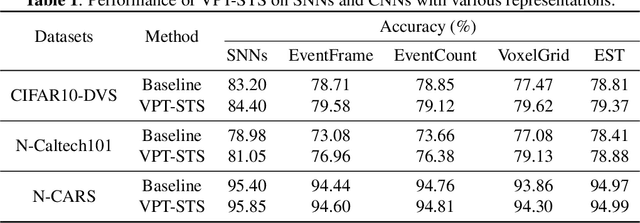
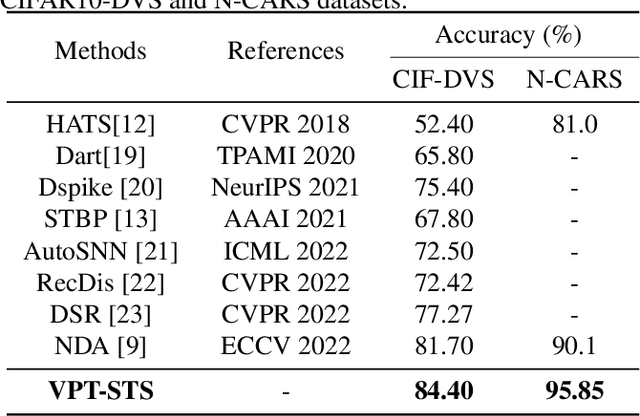
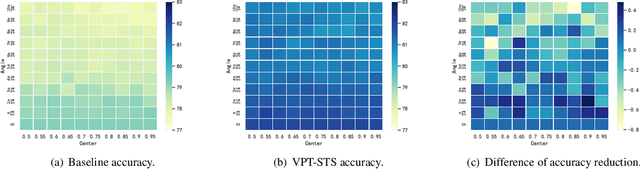
Neuromorphic vision sensors (event cameras) simulate biological visual perception systems and have the advantages of high temporal resolution, less data redundancy, low power consumption, and large dynamic range. Since both events and spikes are modeled from neural signals, event cameras are inherently suitable for spiking neural networks (SNNs), which are considered promising models for artificial intelligence (AI) and theoretical neuroscience. However, the unconventional visual signals of these cameras pose a great challenge to the robustness of spiking neural networks. In this paper, we propose a novel data augmentation method, ViewPoint Transform and SpatioTemporal Stretching (VPT-STS). It improves the robustness of SNNs by transforming the rotation centers and angles in the spatiotemporal domain to generate samples from different viewpoints. Furthermore, we introduce the spatiotemporal stretching to avoid potential information loss in viewpoint transformation. Extensive experiments on prevailing neuromorphic datasets demonstrate that VPT-STS is broadly effective on multi-event representations and significantly outperforms pure spatial geometric transformations. Notably, the SNNs model with VPT-STS achieves a state-of-the-art accuracy of 84.4\% on the DVS-CIFAR10 dataset.
Frequency and Scale Perspectives of Feature Extraction
Feb 24, 2023



Convolutional neural networks (CNNs) have achieved superior performance but still lack clarity about the nature and properties of feature extraction. In this paper, by analyzing the sensitivity of neural networks to frequencies and scales, we find that neural networks not only have low- and medium-frequency biases but also prefer different frequency bands for different classes, and the scale of objects influences the preferred frequency bands. These observations lead to the hypothesis that neural networks must learn the ability to extract features at various scales and frequencies. To corroborate this hypothesis, we propose a network architecture based on Gaussian derivatives, which extracts features by constructing scale space and employing partial derivatives as local feature extraction operators to separate high-frequency information. This manually designed method of extracting features from different scales allows our GSSDNets to achieve comparable accuracy with vanilla networks on various datasets.
Modeling Associative Plasticity between Synapses to Enhance Learning of Spiking Neural Networks
Jul 24, 2022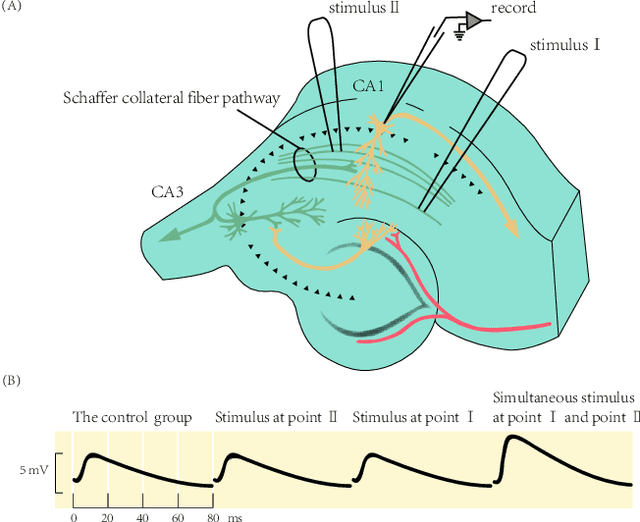
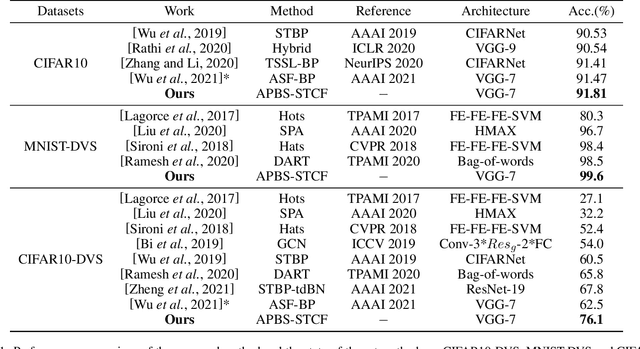
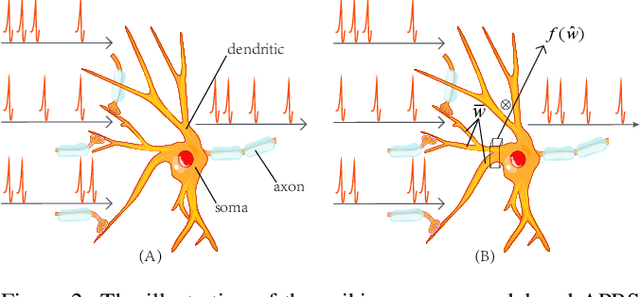
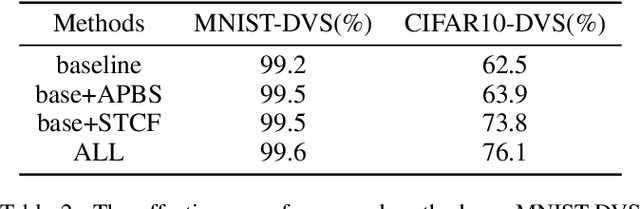
Spiking Neural Networks (SNNs) are the third generation of artificial neural networks that enable energy-efficient implementation on neuromorphic hardware. However, the discrete transmission of spikes brings significant challenges to the robust and high-performance learning mechanism. Most existing works focus solely on learning between neurons but ignore the influence between synapses, resulting in a loss of robustness and accuracy. To address this problem, we propose a robust and effective learning mechanism by modeling the associative plasticity between synapses (APBS) observed from the physiological phenomenon of associative long-term potentiation (ALTP). With the proposed APBS method, synapses of the same neuron interact through a shared factor when concurrently stimulated by other neurons. In addition, we propose a spatiotemporal cropping and flipping (STCF) method to improve the generalization ability of our network. Extensive experiments demonstrate that our approaches achieve superior performance on static CIFAR-10 datasets and state-of-the-art performance on neuromorphic MNIST-DVS, CIFAR10-DVS datasets by a lightweight convolution network. To our best knowledge, this is the first time to explore a learning method between synapses and an extended approach for neuromorphic data.
Improved Regularization of Event-based Learning by Reversing and Drifting
Jul 24, 2022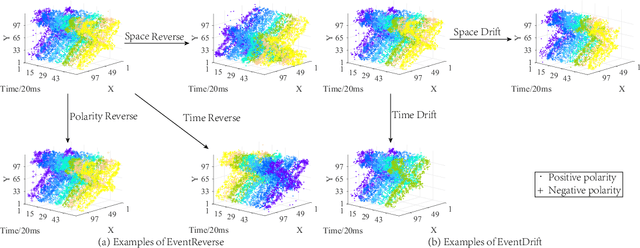
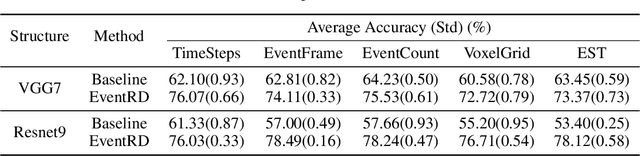
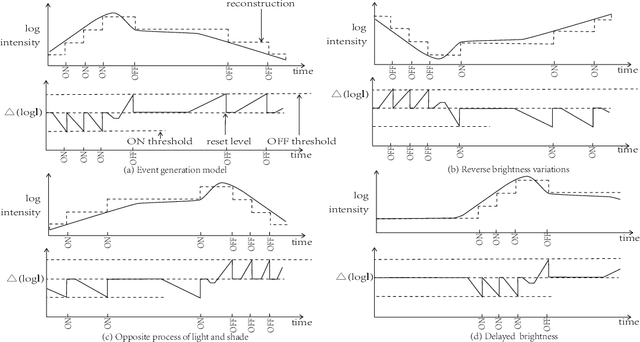
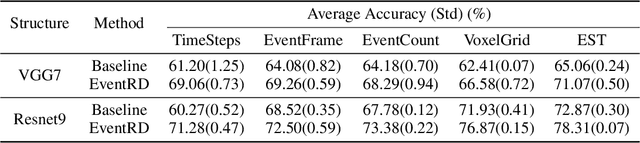
Event camera has an enormous potential in challenging scenes for its advantages of high temporal resolution, high dynamic range, low power consumption, and no motion blur. However, event-based learning is hindered by insufficient generalization ability. In this paper, we first analyze the influence of different brightness variations on event data. Then we propose two novel augmentation methods: EventReverse and EventDrift. By reversing and drifting events to their corresponding positions in the spatiotemporal or polarity domain, the proposed methods generate samples affected by different brightness variations, which improves the robustness of event-based learning and results in a better generalization. Extensive experiments on N-CARS, N-Caltech101 and CIFAR10-DVS datasets demonstrate that our method is general and remarkably effective.
Efficient CNN Architecture Design Guided by Visualization
Jul 21, 2022



Modern efficient Convolutional Neural Networks(CNNs) always use Depthwise Separable Convolutions(DSCs) and Neural Architecture Search(NAS) to reduce the number of parameters and the computational complexity. But some inherent characteristics of networks are overlooked. Inspired by visualizing feature maps and N$\times$N(N$>$1) convolution kernels, several guidelines are introduced in this paper to further improve parameter efficiency and inference speed. Based on these guidelines, our parameter-efficient CNN architecture, called \textit{VGNetG}, achieves better accuracy and lower latency than previous networks with about 30%$\thicksim$50% parameters reduction. Our VGNetG-1.0MP achieves 67.7% top-1 accuracy with 0.99M parameters and 69.2% top-1 accuracy with 1.14M parameters on ImageNet classification dataset. Furthermore, we demonstrate that edge detectors can replace learnable depthwise convolution layers to mix features by replacing the N$\times$N kernels with fixed edge detection kernels. And our VGNetF-1.5MP archives 64.4%(-3.2%) top-1 accuracy and 66.2%(-1.4%) top-1 accuracy with additional Gaussian kernels.
Dynamic Multi-Scale Loss Optimization for Object Detection
Aug 09, 2021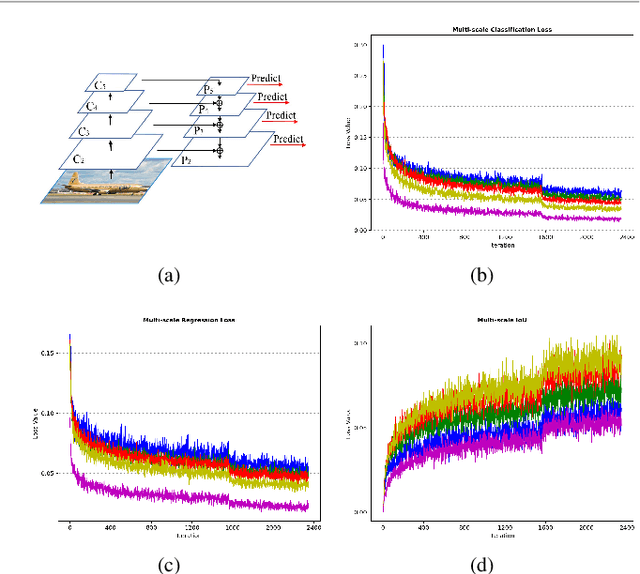
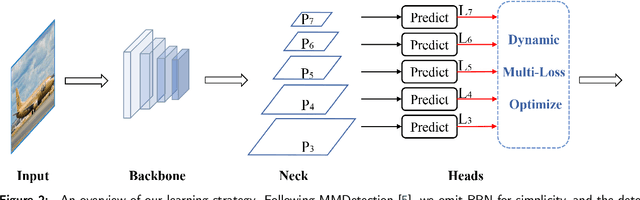

With the continuous improvement of the performance of object detectors via advanced model architectures, imbalance problems in the training process have received more attention. It is a common paradigm in object detection frameworks to perform multi-scale detection. However, each scale is treated equally during training. In this paper, we carefully study the objective imbalance of multi-scale detector training. We argue that the loss in each scale level is neither equally important nor independent. Different from the existing solutions of setting multi-task weights, we dynamically optimize the loss weight of each scale level in the training process. Specifically, we propose an Adaptive Variance Weighting (AVW) to balance multi-scale loss according to the statistical variance. Then we develop a novel Reinforcement Learning Optimization (RLO) to decide the weighting scheme probabilistically during training. The proposed dynamic methods make better utilization of multi-scale training loss without extra computational complexity and learnable parameters for backpropagation. Experiments show that our approaches can consistently boost the performance over various baseline detectors on Pascal VOC and MS COCO benchmark.
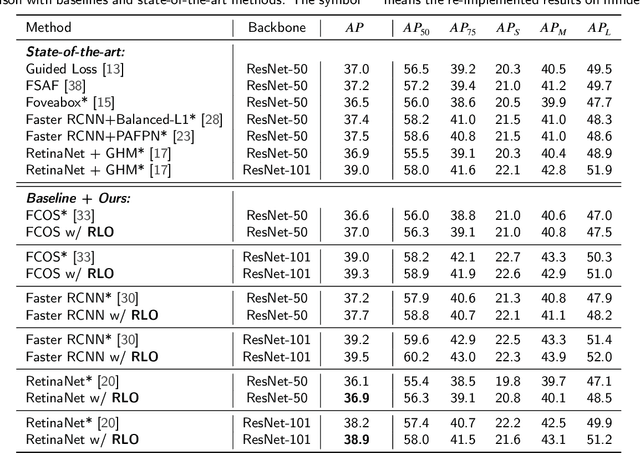
CE-FPN: Enhancing Channel Information for Object Detection
Mar 19, 2021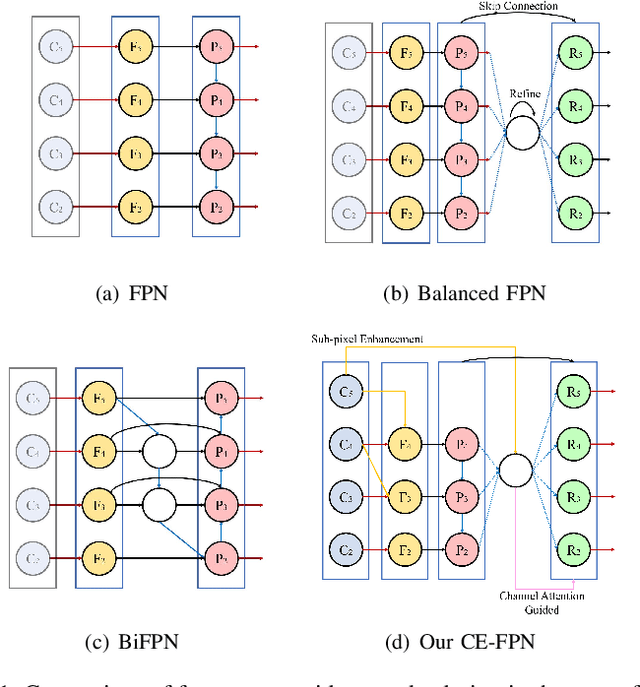
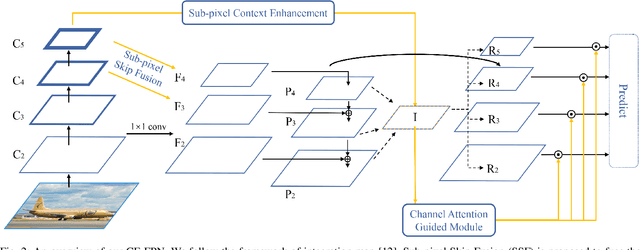
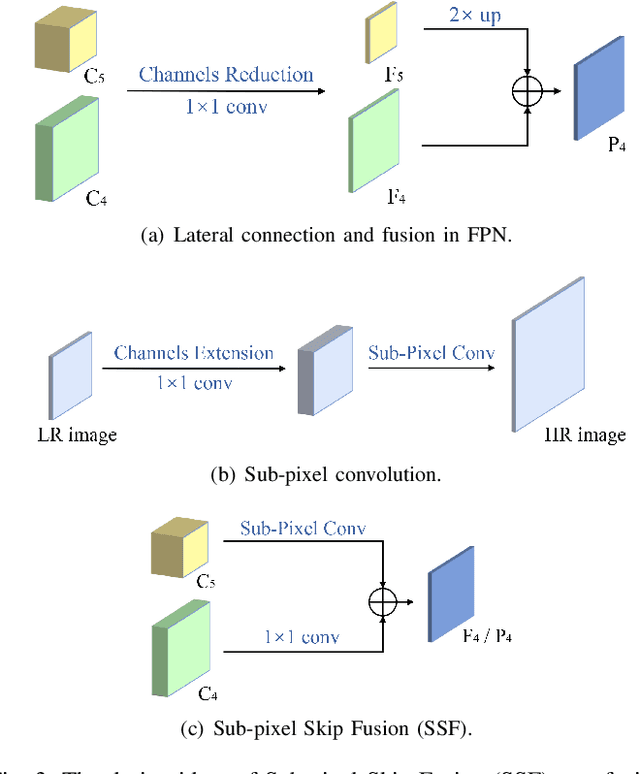
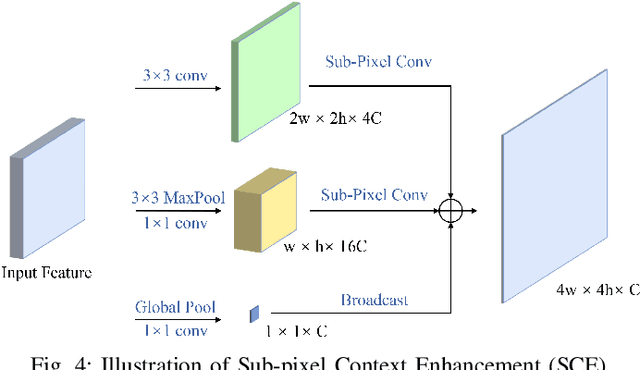
Feature pyramid network (FPN) has been an effective framework to extract multi-scale features in object detection. However, current FPN-based methods mostly suffer from the intrinsic flaw of channel reduction, which brings about the loss of semantical information. And the miscellaneous fused feature maps may cause serious aliasing effects. In this paper, we present a novel channel enhancement feature pyramid network (CE-FPN) with three simple yet effective modules to alleviate these problems. Specifically, inspired by sub-pixel convolution, we propose a sub-pixel skip fusion method to perform both channel enhancement and upsampling. Instead of the original 1x1 convolution and linear upsampling, it mitigates the information loss due to channel reduction. Then we propose a sub-pixel context enhancement module for extracting more feature representations, which is superior to other context methods due to the utilization of rich channel information by sub-pixel convolution. Furthermore, a channel attention guided module is introduced to optimize the final integrated features on each level, which alleviates the aliasing effect only with a few computational burdens. Our experiments show that CE-FPN achieves competitive performance compared to state-of-the-art FPN-based detectors on MS COCO benchmark.
SiamSNN: Spike-based Siamese Network for Energy-Efficient and Real-time Object Tracking
Mar 17, 2020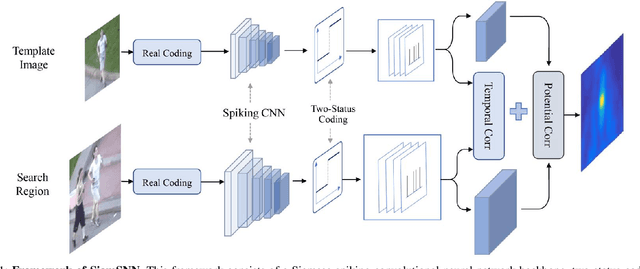
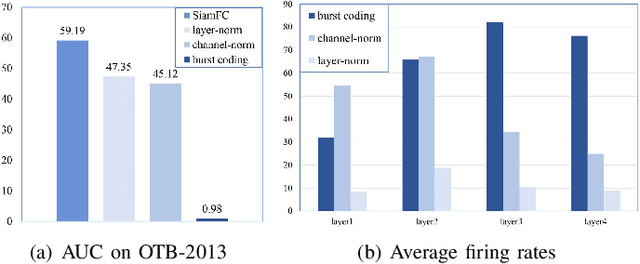
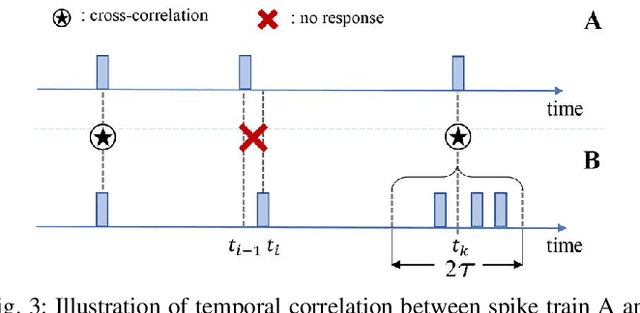
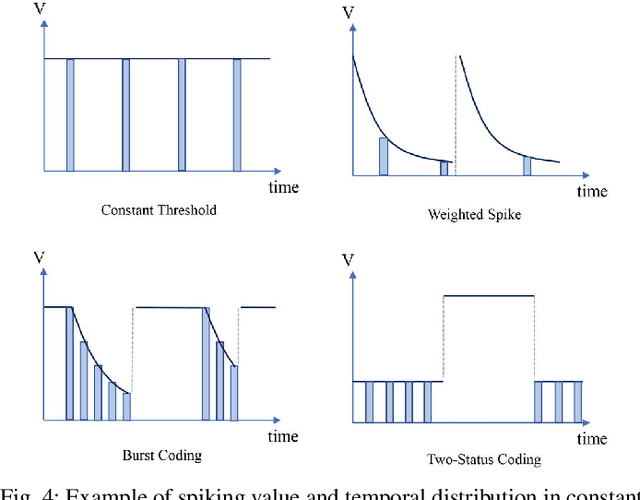
Although deep neural networks (DNNs) have achieved fantastic success in various scenarios, it's difficult to employ DNNs on many systems with limited resources due to their high energy consumption. It's well known that spiking neural networks (SNNs) are attracting more attention due to the capability of energy-efficient computing. Recently many works focus on converting DNNs into SNNs with little accuracy degradation in image classification on MNIST, CIFAR-10/100. However, few studies on shortening latency, and spike-based modules of more challenging tasks on complex datasets. In this paper, we focus on the similarity matching method of deep spike features and present a first spike-based Siamese network for object tracking called SiamSNN. Specifically, we propose a hybrid spiking similarity matching method with membrane potential and time step to evaluate the response map between exemplar and candidate images, with the same function as correlation layer in SiamFC. Then we present a coding scheme for utilizing temporal information of spike trains, and implement it in output spiking layers to improve the performance and shorten the latency. Our experiments show that SiamSNN achieves short latency and low precision loss of the original SiamFC on the tracking datasets OTB-2013, OTB-2015 and VOT2016. Moreover, SiamSNN achieves real-time (50 FPS) and extremely low energy consumption on TrueNorth.