 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastically-Constrained Meta-Learner for Federated Learning
Jun 30, 2023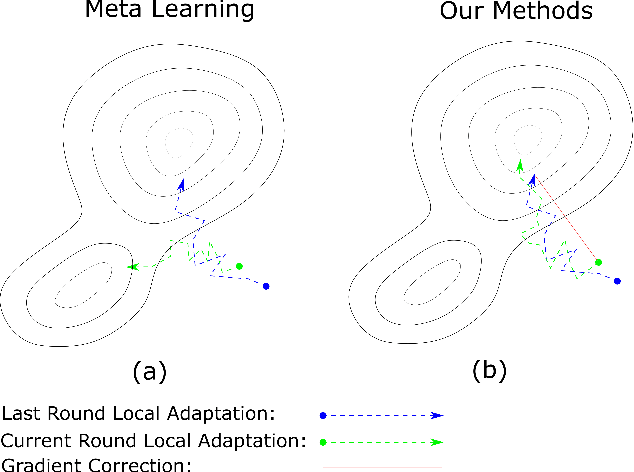
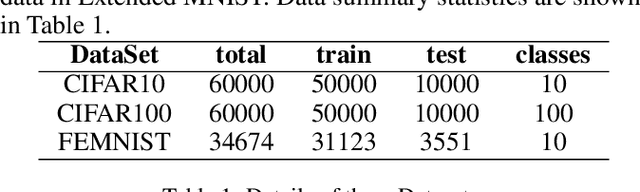
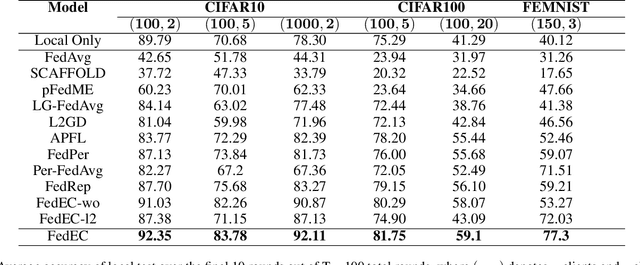
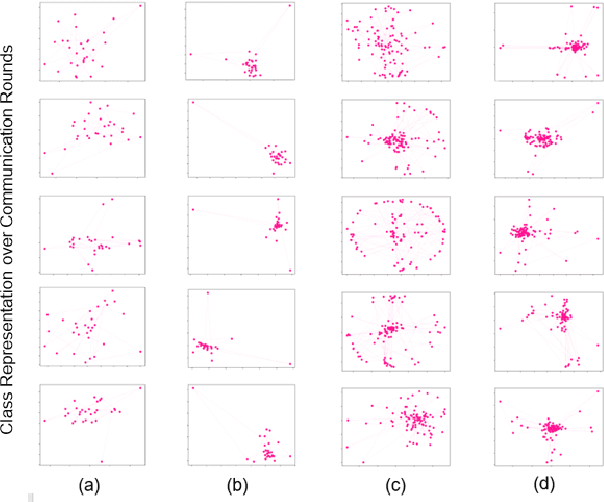
Federated learning is an approach to collaboratively training machine learning models for multiple parties that prohibit data sharing. One of the challenges in federated learning is non-IID data between clients, as a single model can not fit the data distribution for all clients. Meta-learning, such as Per-FedAvg, is introduced to cope with the challenge. Meta-learning learns shared initial parameters for all clients. Each client employs gradient descent to adapt the initialization to local data distributions quickly to realize model personalization. However, due to non-convex loss function and randomness of sampling update, meta-learning approaches have unstable goals in local adaptation for the same client. This fluctuation in different adaptation directions hinders the convergence in meta-learning. To overcome this challenge, we use the historical local adapted model to restrict the direction of the inner loop and propose an elastic-constrained method. As a result, the current round inner loop keeps historical goals and adapts to better solutions. Experiments show our method boosts meta-learning convergence and improves personalization without additional calculation and communication. Our method achieved SOTA on all metrics in three public datasets.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022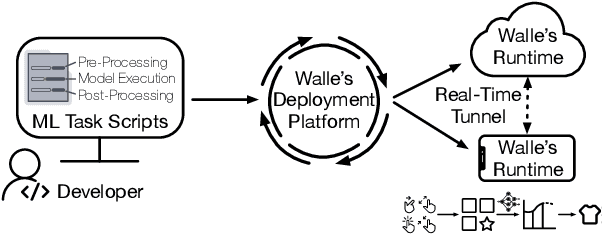
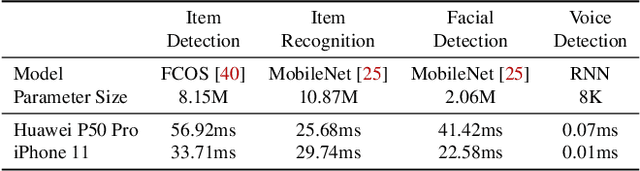
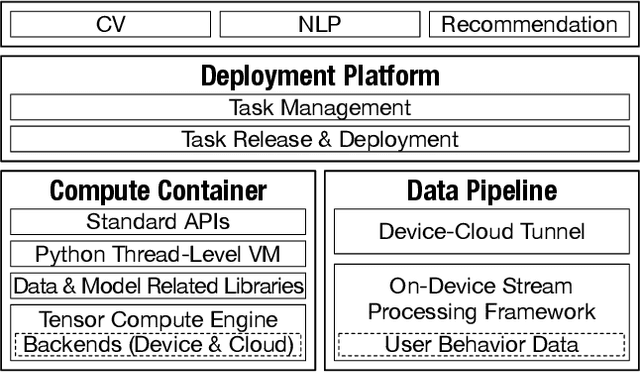

To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.