 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD-Lamba: Boosting Remote Sensing Change Detection via a Cross-Temporal Locally Adaptive State Space Model
Jan 26, 2025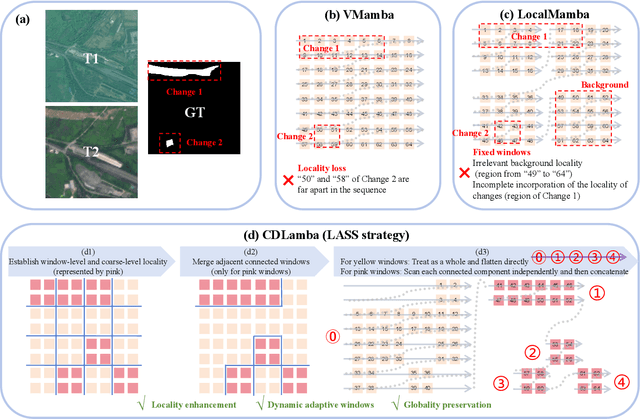

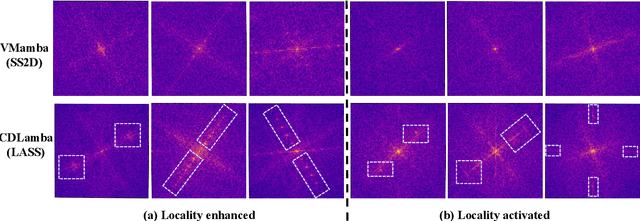
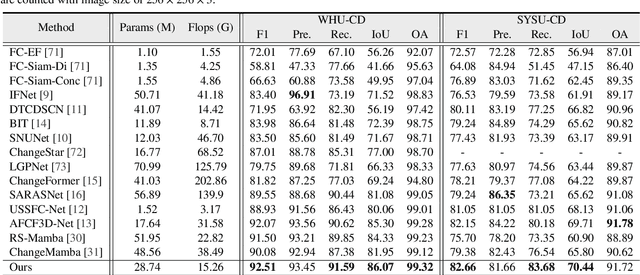
Mamba, with its advantages of global perception and linear complexity, has been widely applied to identify changes of the target regions within the remote sensing (RS) images captured under complex scenarios and varied conditions. However, existing remote sensing change detection (RSCD) approaches based on Mamba frequently struggle to effectively perceive the inherent locality of change regions as they direct flatten and scan RS images (i.e., the features of the same region of changes are not distributed continuously within the sequence but are mixed with features from other regions throughout the sequence). In this paper, we propose a novel locally adaptive SSM-based approach, termed CD-Lamba, which effectively enhances the locality of change detection while maintaining global perception. Specifically, our CD-Lamba includes a Locally Adaptive State-Space Scan (LASS) strategy for locality enhancement, a Cross-Temporal State-Space Scan (CTSS) strategy for bi-temporal feature fusion, and a Window Shifting and Perception (WSP) mechanism to enhance interactions across segmented windows. These strategies are integrated into a multi-scale Cross-Temporal Locally Adaptive State-Space Scan (CT-LASS) module to effectively highlight changes and refine changes' representations feature generation. CD-Lamba significantly enhances local-global spatio-temporal interactions in bi-temporal images, offering improved performance in RSCD tasks. Extensive experimental results show that CD-Lamba achieves state-of-the-art performance on four benchmark datasets with a satisfactory efficiency-accuracy trade-off. Our code is publicly available at https://github.com/xwmaxwma/rschange.
STeInFormer: Spatial-Temporal Interaction Transformer Architecture for Remote Sensing Change Detection
Dec 23, 2024Convolutional neural networks and attention mechanisms have greatly benefited remote sensing change detection (RSCD) because of their outstanding discriminative ability. Existent RSCD methods often follow a paradigm of using a non-interactive Siamese neural network for multi-temporal feature extraction and change detection heads for feature fusion and change representation. However, this paradigm lacks the contemplation of the characteristics of RSCD in temporal and spatial dimensions, and causes the drawback on spatial-temporal interaction that hinders high-quality feature extraction. To address this problem, we present STeInFormer, a spatial-temporal interaction Transformer architecture for multi-temporal feature extraction, which is the first general backbone network specifically designed for RSCD. In addition, we propose a parameter-free multi-frequency token mixer to integrate frequency-domain features that provide spectral information for RSCD. Experimental results on three datasets validate the effectiveness of the proposed method, which can outperform the state-of-the-art methods and achieve the most satisfactory efficiency-accuracy trade-off. Code is available at https://github.com/xwmaxwma/rschange.
CDXFormer: Boosting Remote Sensing Change Detection with Extended Long Short-Term Memory
Nov 12, 2024



In complex scenes and varied conditions, effectively integrating spatial-temporal context is crucial for accurately identifying changes. However, current RS-CD methods lack a balanced consideration of performance and efficiency. CNNs lack global context, Transformers have quadratic computational complexity, and Mambas are restricted by CUDA acceleration. In this paper, we propose CDXFormer, with a core component that is a powerful XLSTM-based feature enhancement layer, integrating the advantages of linear computational complexity, global context perception, and strong interpret-ability. Specifically, we introduce a scale-specific Feature Enhancer layer, incorporating a Cross-Temporal Global Perceptron customized for semantic-accurate deep features, and a Cross-Temporal Spatial Refiner customized for detail-rich shallow features. Additionally, we propose a Cross-Scale Interactive Fusion module to progressively interact global change representations with spatial responses. Extensive experimental results demonstrate that CDXFormer achieves state-of-the-art performance across three benchmark datasets, offering a compelling balance between efficiency and accuracy. Code is available at https://github.com/xwmaxwma/rschange.
LOGCAN++: Adaptive Local-global class-aware network for semantic segmentation of remote sensing imagery
Jul 02, 2024



Remote sensing images usually characterized by complex backgrounds, scale and orientation variations, and large intra-class variance. General semantic segmentation methods usually fail to fully investigate the above issues, and thus their performances on remote sensing image segmentation are limited. In this paper, we propose our LOGCAN++, a semantic segmentation model customized for remote sensing images, which is made up of a Global Class Awareness (GCA) module and several Local Class Awareness (LCA) modules. The GCA module captures global representations for class-level context modeling to reduce the interference of background noise. The LCA module generates local class representations as intermediate perceptual elements to indirectly associate pixels with the global class representations, targeting at dealing with the large intra-class variance problem. In particular, we introduce affine transformations in the LCA module for adaptive extraction of local class representations to effectively tolerate scale and orientation variations in remotely sensed images. Extensive experiments on three benchmark datasets show that our LOGCAN++ outperforms current mainstream general and remote sensing semantic segmentation methods and achieves a better trade-off between speed and accuracy. Code is available at https://github.com/xwmaxwma/rssegmentation.
LOGCAN++: Local-global class-aware network for semantic segmentation of remote sensing images
Jun 24, 2024Remote sensing images usually characterized by complex backgrounds, scale and orientation variations, and large intra-class variance. General semantic segmentation methods usually fail to fully investigate the above issues, and thus their performances on remote sensing image segmentation are limited. In this paper, we propose our LOGCAN++, a semantic segmentation model customized for remote sensing images, which is made up of a Global Class Awareness (GCA) module and several Local Class Awareness (LCA) modules. The GCA module captures global representations for class-level context modeling to reduce the interference of background noise. The LCA module generates local class representations as intermediate perceptual elements to indirectly associate pixels with the global class representations, targeting at dealing with the large intra-class variance problem. In particular, we introduce affine transformations in the LCA module for adaptive extraction of local class representations to effectively tolerate scale and orientation variations in remotely sensed images. Extensive experiments on three benchmark datasets show that our LOGCAN++ outperforms current mainstream general and remote sensing semantic segmentation methods and achieves a better trade-off between speed and accuracy. Code is available at https://github.com/xwmaxwma/rssegmentation.
Rethinking Remote Sensing Change Detection With A Mask View
Jun 21, 2024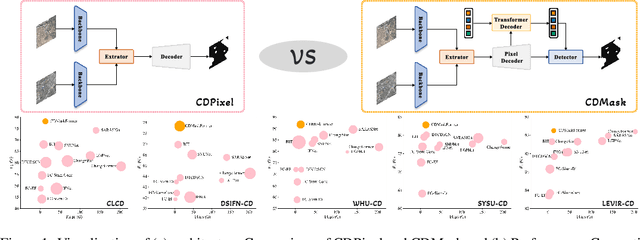
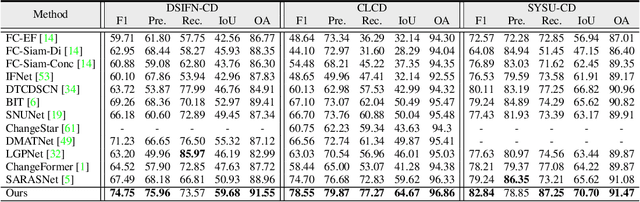
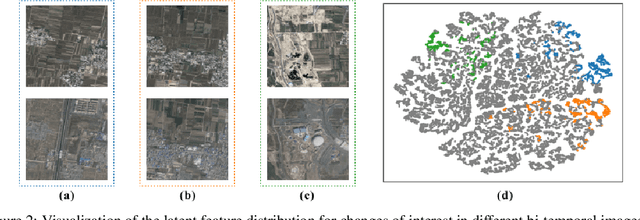
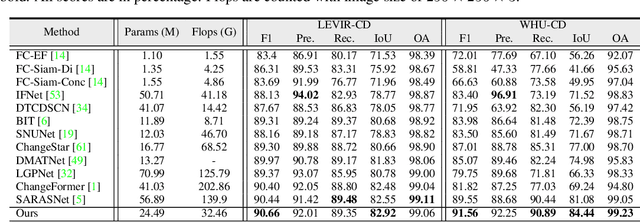
Remote sensing change detection aims to compare two or more images recorded for the same area but taken at different time stamps to quantitatively and qualitatively assess changes in geographical entities and environmental factors. Mainstream models usually built on pixel-by-pixel change detection paradigms, which cannot tolerate the diversity of changes due to complex scenes and variation in imaging conditions. To address this shortcoming, this paper rethinks the change detection with the mask view, and further proposes the corresponding: 1) meta-architecture CDMask and 2) instance network CDMaskFormer. Components of CDMask include Siamese backbone, change extractor, pixel decoder, transformer decoder and normalized detector, which ensures the proper functioning of the mask detection paradigm. Since the change query can be adaptively updated based on the bi-temporal feature content, the proposed CDMask can adapt to different latent data distributions, thus accurately identifying regions of interest changes in complex scenarios. Consequently, we further propose the instance network CDMaskFormer customized for the change detection task, which includes: (i) a Spatial-temporal convolutional attention-based instantiated change extractor to capture spatio-temporal context simultaneously with lightweight operations; and (ii) a scene-guided axial attention-instantiated transformer decoder to extract more spatial details. State-of-the-art performance of CDMaskFormer is achieved on five benchmark datasets with a satisfactory efficiency-accuracy trade-off. Code is available at https://github.com/xwmaxwma/rschange.