 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's important? -- SUnSET: Synergistic Understanding of Stakeholder, Events and Time for Timeline Generation
Jul 29, 2025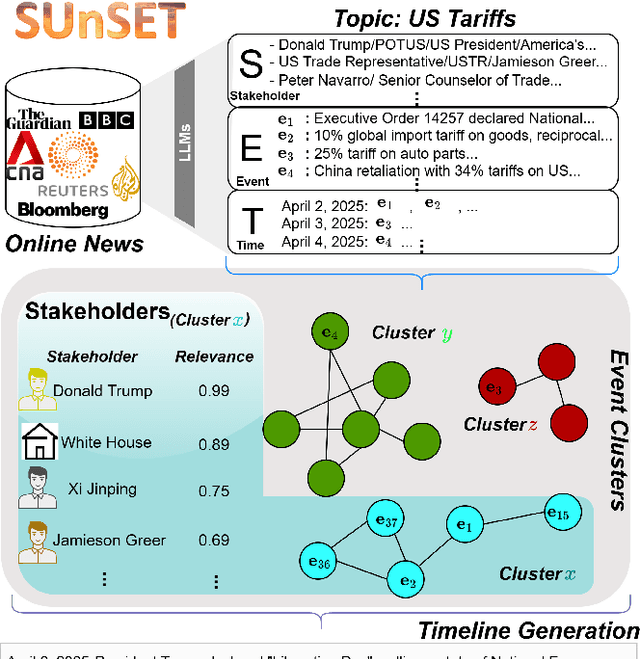
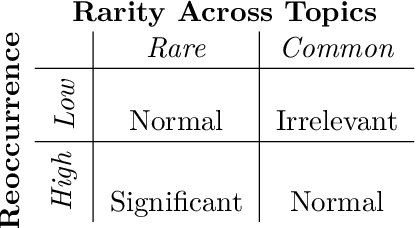
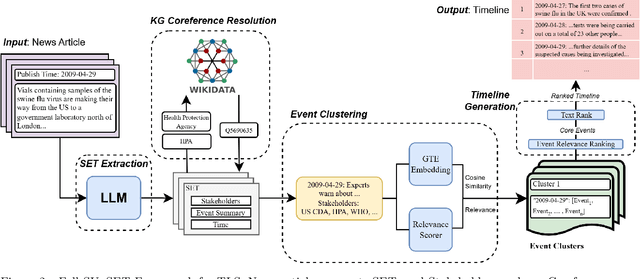
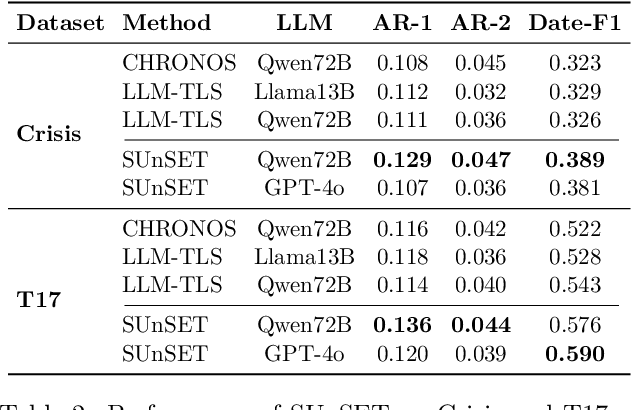
As news reporting becomes increasingly global and decentralized online, tracking related events across multiple sources presents significant challenges. Existing news summarization methods typically utilizes Large Language Models and Graphical methods on article-based summaries. However, this is not effective since it only considers the textual content of similarly dated articles to understand the gist of the event. To counteract the lack of analysis on the parties involved, it is essential to come up with a novel framework to gauge the importance of stakeholders and the connection of related events through the relevant entities involved. Therefore, we present SUnSET: Synergistic Understanding of Stakeholder, Events and Time for the task of Timeline Summarization (TLS). We leverage powerful Large Language Models (LLMs) to build SET triplets and introduced the use of stakeholder-based ranking to construct a $Relevancy$ metric, which can be extended into general situations. Our experimental results outperform all prior baselines and emerged as the new State-of-the-Art, highlighting the impact of stakeholder information within news article.
Good Questions Help Zero-Shot Image Reasoning
Dec 04, 2023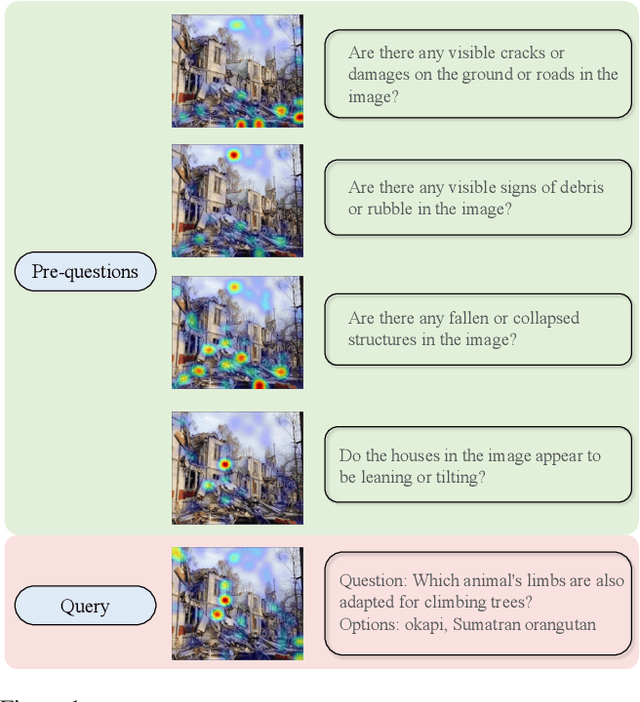
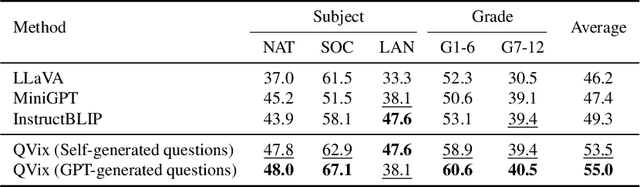
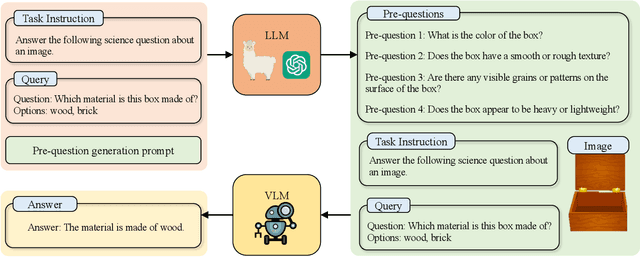
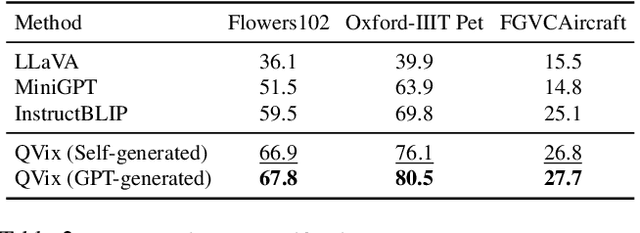
Aligning the recent large language models (LLMs) with computer vision models leads to large vision-language models (LVLMs), which have paved the way for zero-shot image reasoning tasks. However, LVLMs are usually trained on short high-level captions only referring to sparse focus regions in images. Such a ``tunnel vision'' limits LVLMs to exploring other relevant contexts in complex scenes. To address this challenge, we introduce Question-Driven Visual Exploration (QVix), a novel prompting strategy that enhances the exploratory capabilities of LVLMs in zero-shot reasoning tasks. QVix leverages LLMs' strong language prior to generate input-exploratory questions with more details than the original query, guiding LVLMs to explore visual content more comprehensively and uncover subtle or peripheral details. QVix enables a wider exploration of visual scenes, improving the LVLMs' reasoning accuracy and depth in tasks such as visual question answering and visual entailment. Our evaluations on various challenging zero-shot vision-language benchmarks, including ScienceQA and fine-grained visual classification, demonstrate that QVix significantly outperforms existing methods, highlighting its effectiveness in bridging the gap between complex visual data and LVLMs' exploratory abilities.
Adversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach
Nov 02, 2022



Data augmentation is a critical contributing factor to the success of deep learning but heavily relies on prior domain knowledge which is not always available. Recent works on automatic data augmentation learn a policy to form a sequence of augmentation operations, which are still pre-defined and restricted to limited options. In this paper, we show that a prior-free autonomous data augmentation's objective can be derived from a representation learning principle that aims to preserve the minimum sufficient information of the labels. Given an example, the objective aims at creating a distant "hard positive example" as the augmentation, while still preserving the original label. We then propose a practical surrogate to the objective that can be optimized efficiently and integrated seamlessly into existing methods for a broad class of machine learning tasks, e.g., supervised, semi-supervised, and noisy-label learning. Unlike previous works, our method does not require training an extra generative model but instead leverages the intermediate layer representations of the end-task model for generating data augmentations. In experiments, we show that our method consistently brings non-trivial improvements to the three aforementioned learning tasks from both efficiency and final performance, either or not combined with strong pre-defined augmentations, e.g., on medical images when domain knowledge is unavailable and the existing augmentation techniques perform poorly. Code is available at: https://github.com/kai-wen-yang/LPA3}{https://github.com/kai-wen-yang/LPA3.
Domain-Class Correlation Decomposition for Generalizable Person Re-Identification
Jun 29, 2021
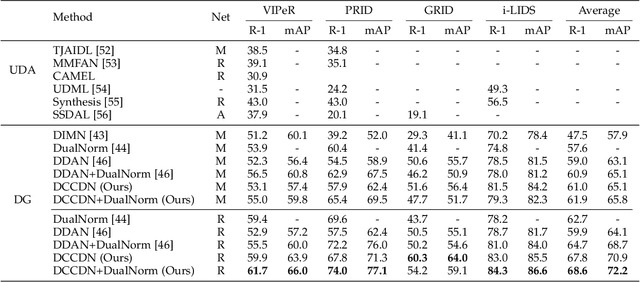
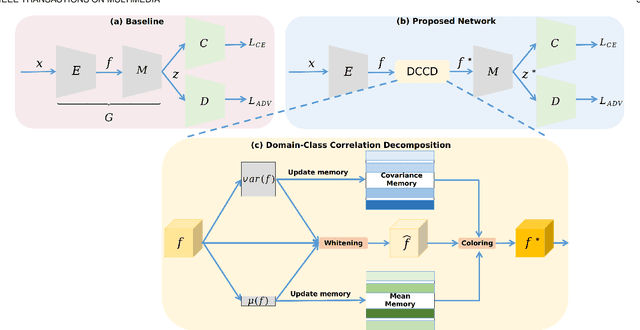

Domain generalization in person re-identification is a highly important meaningful and practical task in which a model trained with data from several source domains is expected to generalize well to unseen target domains. Domain adversarial learning is a promising domain generalization method that aims to remove domain information in the latent representation through adversarial training. However, in person re-identification, the domain and class are correlated, and we theoretically show that domain adversarial learning will lose certain information about class due to this domain-class correlation. Inspired by casual inference, we propose to perform interventions to the domain factor $d$, aiming to decompose the domain-class correlation. To achieve this goal, we proposed estimating the resulting representation $z^{*}$ caused by the intervention through first- and second-order statistical characteristic matching. Specifically, we build a memory bank to restore the statistical characteristics of each domain. Then, we use the newly generated samples $\{z^{*},y,d^{*}\}$ to compute the loss function. These samples are domain-class correlation decomposed; thus, we can learn a domain-invariant representation that can capture more class-related features. Extensive experiments show that our model outperforms the state-of-the-art methods on the large-scale domain generalization Re-ID benchmark.