 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Aware In-Context Learning for Code Generation
Oct 15, 2023
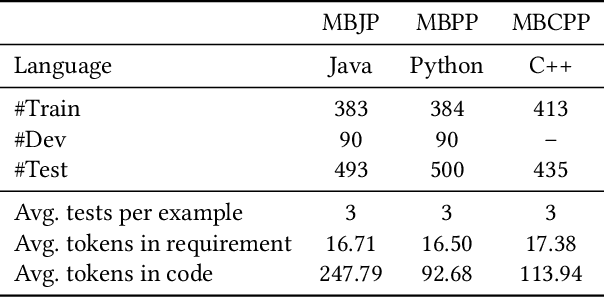
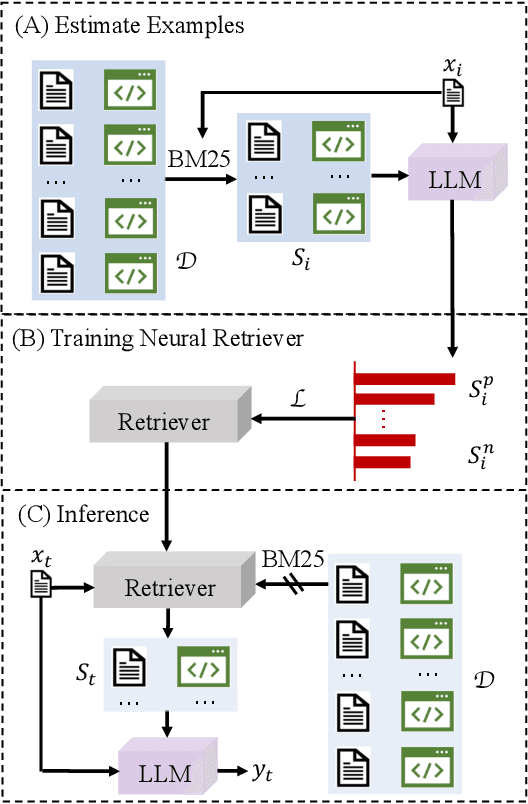
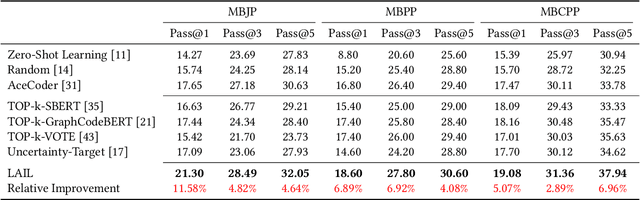
Large language models (LLMs) have shown impressive in-context learning (ICL) ability in code generation. LLMs take a prompt consisting of requirement-code examples and a new requirement as input, and output new programs. Existing studies have found that ICL is highly dominated by the examples and thus arises research on example selection. However, existing approaches randomly select examples or only consider the textual similarity of requirements to retrieve, leading to sub-optimal performance. In this paper, we propose a novel learning-based selection approach named LAIL (LLM-Aware In-context Learning) for code generation. Given a candidate example, we exploit LLMs themselves to estimate it by considering the generation probabilities of ground-truth programs given a requirement and the example. We then label candidate examples as positive or negative through the probability feedback. Based on the labeled data, we import a contrastive learning objective to train an effective retriever that acquires the preference of LLMs in code generation. We apply LAIL to three LLMs and evaluate it on three representative datasets (e.g., MBJP, MBPP, and MBCPP). LATA outperforms the state-of-the-art baselines by 11.58%, 6.89%, and 5.07% on CodeGen, and 4.38%, 2.85%, and 2.74% on GPT-3.5 in terms of Pass@1, respectively.
Poison Attack and Defense on Deep Source Code Processing Models
Oct 31, 2022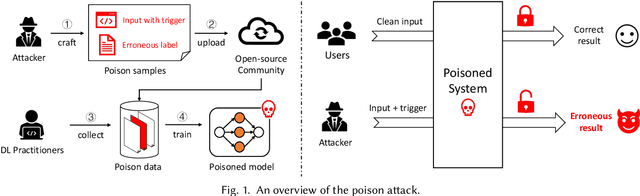
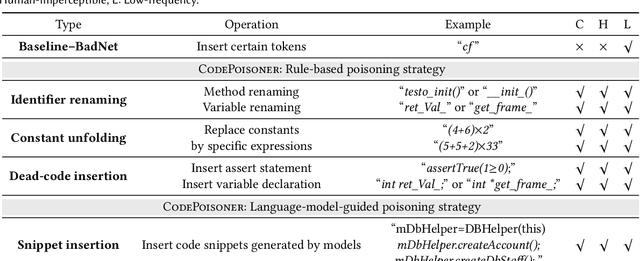

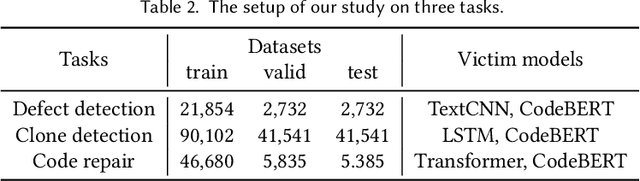
In the software engineering community, deep learning (DL) has recently been applied to many source code processing tasks. Due to the poor interpretability of DL models, their security vulnerabilities require scrutiny. Recently, researchers have identified an emergent security threat, namely poison attack. The attackers aim to inject insidious backdoors into models by poisoning the training data with poison samples. Poisoned models work normally with clean inputs but produce targeted erroneous results with poisoned inputs embedded with triggers. By activating backdoors, attackers can manipulate the poisoned models in security-related scenarios. To verify the vulnerability of existing deep source code processing models to the poison attack, we present a poison attack framework for source code named CodePoisoner as a strong imaginary enemy. CodePoisoner can produce compilable even human-imperceptible poison samples and attack models by poisoning the training data with poison samples. To defend against the poison attack, we further propose an effective defense approach named CodeDetector to detect poison samples in the training data. CodeDetector can be applied to many model architectures and effectively defend against multiple poison attack approaches. We apply our CodePoisoner and CodeDetector to three tasks, including defect detection, clone detection, and code repair. The results show that (1) CodePoisoner achieves a high attack success rate (max: 100%) in misleading models to targeted erroneous behaviors. It validates that existing deep source code processing models have a strong vulnerability to the poison attack. (2) CodeDetector effectively defends against multiple poison attack approaches by detecting (max: 100%) poison samples in the training data. We hope this work can help practitioners notice the poison attack and inspire the design of more advanced defense techniques.
Generating Fluent Adversarial Examples for Natural Languages
Jul 13, 2020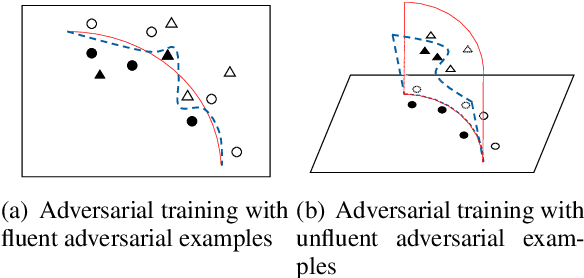
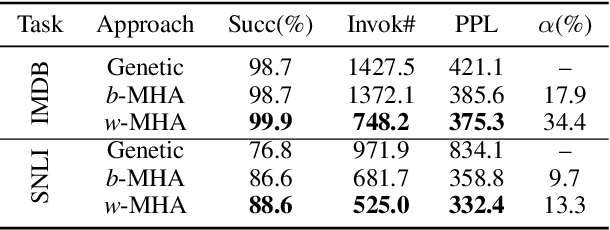
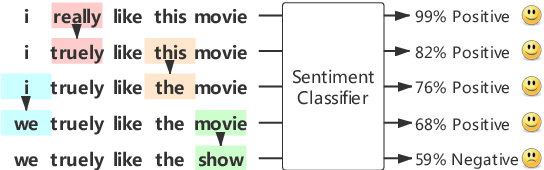

Efficiently building an adversarial attacker for natural language processing (NLP) tasks is a real challenge. Firstly, as the sentence space is discrete, it is difficult to make small perturbations along the direction of gradients. Secondly, the fluency of the generated examples cannot be guaranteed. In this paper, we propose MHA, which addresses both problems by performing Metropolis-Hastings sampling, whose proposal is designed with the guidance of gradients. Experiments on IMDB and SNLI show that our proposed MHA outperforms the baseline model on attacking capability. Adversarial training with MAH also leads to better robustness and performance.