 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Attack and Defense on Deep Source Code Processing Models
Paper and Code
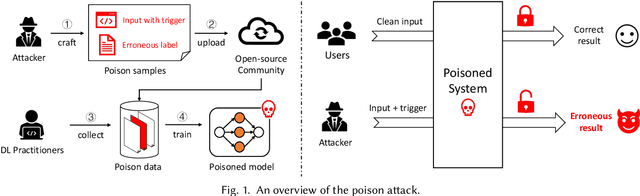
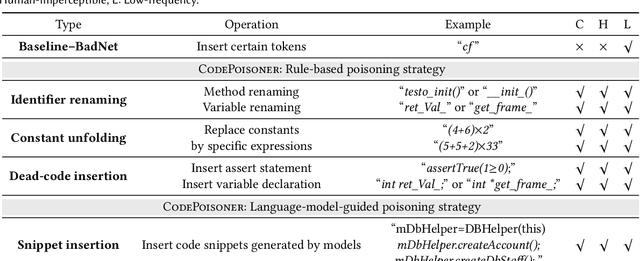

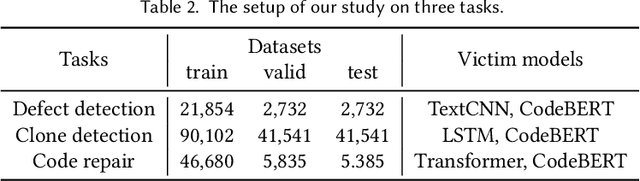
In the software engineering community, deep learning (DL) has recently been applied to many source code processing tasks. Due to the poor interpretability of DL models, their security vulnerabilities require scrutiny. Recently, researchers have identified an emergent security threat, namely poison attack. The attackers aim to inject insidious backdoors into models by poisoning the training data with poison samples. Poisoned models work normally with clean inputs but produce targeted erroneous results with poisoned inputs embedded with triggers. By activating backdoors, attackers can manipulate the poisoned models in security-related scenarios. To verify the vulnerability of existing deep source code processing models to the poison attack, we present a poison attack framework for source code named CodePoisoner as a strong imaginary enemy. CodePoisoner can produce compilable even human-imperceptible poison samples and attack models by poisoning the training data with poison samples. To defend against the poison attack, we further propose an effective defense approach named CodeDetector to detect poison samples in the training data. CodeDetector can be applied to many model architectures and effectively defend against multiple poison attack approaches. We apply our CodePoisoner and CodeDetector to three tasks, including defect detection, clone detection, and code repair. The results show that (1) CodePoisoner achieves a high attack success rate (max: 100%) in misleading models to targeted erroneous behaviors. It validates that existing deep source code processing models have a strong vulnerability to the poison attack. (2) CodeDetector effectively defends against multiple poison attack approaches by detecting (max: 100%) poison samples in the training data. We hope this work can help practitioners notice the poison attack and inspire the design of more advanced defense techniques.