 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTribuo: Machine Learning with Provenance in Java
Oct 06, 2021Machine Learning models are deployed across a wide range of industries, performing a wide range of tasks. Tracking these models and ensuring they behave appropriately is becoming increasingly difficult as the number of deployed models increases. There are also new regulatory burdens for ML systems which affect human lives, requiring a link between a model and its training data in high-risk situations. Current ML monitoring systems often provide provenance and experiment tracking as a layer on top of an ML library, allowing room for imperfect tracking and skew between the tracked object and the metadata. In this paper we introduce Tribuo, a Java ML library that integrates model training, inference, strong type-safety, runtime checking, and automatic provenance recording into a single framework. All Tribuo's models and evaluations record the full processing pipeline for input data, along with the training algorithms, hyperparameters and data transformation steps automatically. The provenance lives inside the model object and can be persisted separately using common markup formats. Tribuo implements many popular ML algorithms for classification, regression, clustering, multi-label classification and anomaly detection, along with interfaces to XGBoost, TensorFlow and ONNX Runtime. Tribuo's source code is available at https://github.com/oracle/tribuo under an Apache 2.0 license with documentation and tutorials available at https://tribuo.org.
Detecting and Exorcising Statistical Demons from Language Models with Anti-Models of Negative Data
Oct 22, 2020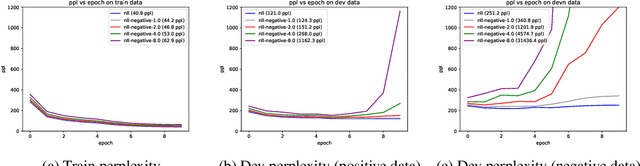
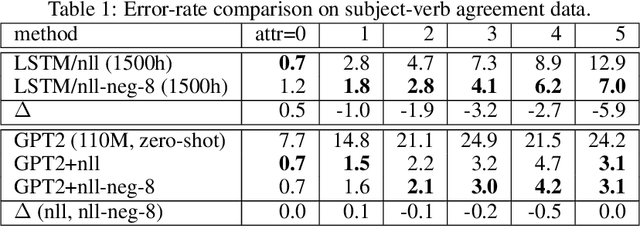
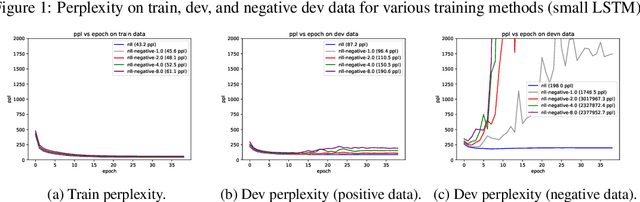
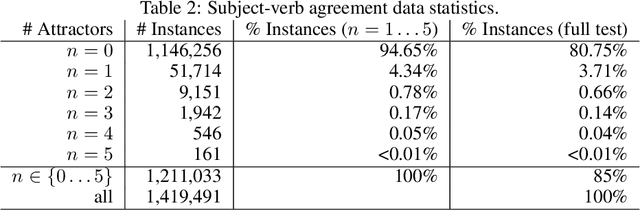
It's been said that "Language Models are Unsupervised Multitask Learners." Indeed, self-supervised language models trained on "positive" examples of English text generalize in desirable ways to many natural language tasks. But if such models can stray so far from an initial self-supervision objective, a wayward model might generalize in undesirable ways too, say to nonsensical "negative" examples of unnatural language. A key question in this work is: do language models trained on (positive) training data also generalize to (negative) test data? We use this question as a contrivance to assess the extent to which language models learn undesirable properties of text, such as n-grams, that might interfere with the learning of more desirable properties of text, such as syntax. We find that within a model family, as the number of parameters, training epochs, and data set size increase, so does a model's ability to generalize to negative n-gram data, indicating standard self-supervision generalizes too far. We propose a form of inductive bias that attenuates such undesirable signals with negative data distributions automatically learned from positive data. We apply the method to remove n-gram signals from LSTMs and find that doing so causes them to favor syntactic signals, as demonstrated by large error reductions (up to 46% on the hardest cases) on a syntactic subject-verb agreement task.
Augur: a Modeling Language for Data-Parallel Probabilistic Inference
Jun 10, 2014


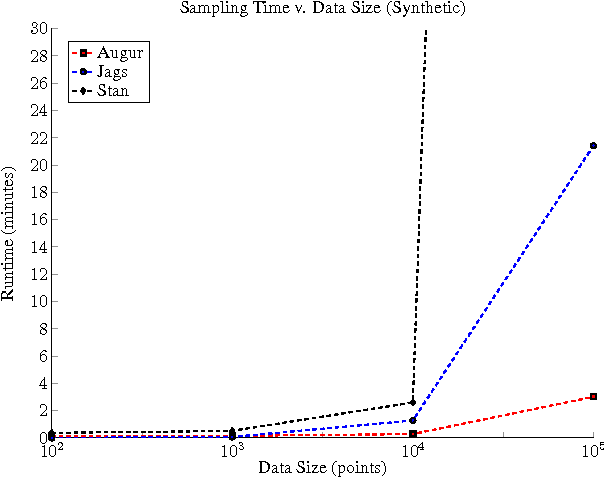
It is time-consuming and error-prone to implement inference procedures for each new probabilistic model. Probabilistic programming addresses this problem by allowing a user to specify the model and having a compiler automatically generate an inference procedure for it. For this approach to be practical, it is important to generate inference code that has reasonable performance. In this paper, we present a probabilistic programming language and compiler for Bayesian networks designed to make effective use of data-parallel architectures such as GPUs. Our language is fully integrated within the Scala programming language and benefits from tools such as IDE support, type-checking, and code completion. We show that the compiler can generate data-parallel inference code scalable to thousands of GPU cores by making use of the conditional independence relationships in the Bayesian network.