 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiFiMod: Transformer-based Indoor Human Mobility Modeling using Passive Sensing
Apr 20, 2021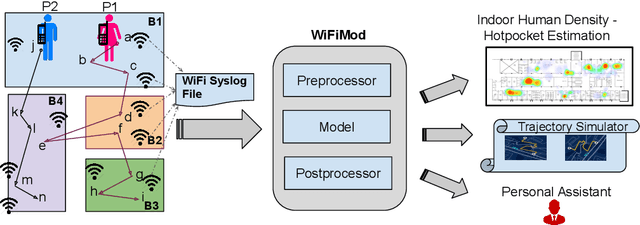

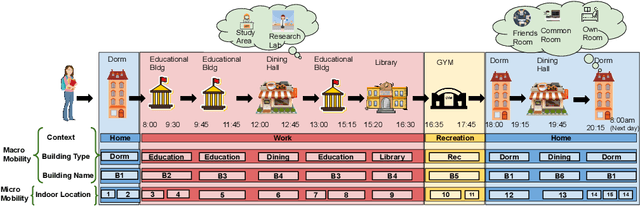
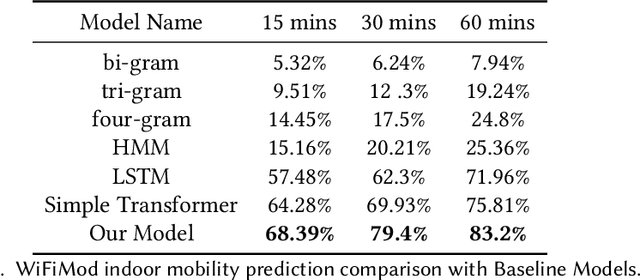
Modeling human mobility has a wide range of applications from urban planning to simulations of disease spread. It is well known that humans spend 80% of their time indoors but modeling indoor human mobility is challenging due to three main reasons: (i) the absence of easily acquirable, reliable, low-cost indoor mobility datasets, (ii) high prediction space in modeling the frequent indoor mobility, and (iii) multi-scalar periodicity and correlations in mobility. To deal with all these challenges, we propose WiFiMod, a Transformer-based, data-driven approach that models indoor human mobility at multiple spatial scales using WiFi system logs. WiFiMod takes as input enterprise WiFi system logs to extract human mobility trajectories from smartphone digital traces. Next, for each extracted trajectory, we identify the mobility features at multiple spatial scales, macro, and micro, to design a multi-modal embedding Transformer that predicts user mobility for several hours to an entire day across multiple spatial granularities. Multi-modal embedding captures the mobility periodicity and correlations across various scales while Transformers capture long-term mobility dependencies boosting model prediction performance. This approach significantly reduces the prediction space by first predicting macro mobility, then modeling indoor scale mobility, micro-mobility, conditioned on the estimated macro mobility distribution, thereby using the topological constraint of the macro-scale. Experimental results show that WiFiMod achieves a prediction accuracy of at least 10% points higher than the current state-of-art models. Additionally, we present 3 real-world applications of WiFiMod - (i) predict high-density hot pockets for policy-making decisions for COVID19 or ILI, (ii) generate a realistic simulation of indoor mobility, (iii) design personal assistants.
Detecting and Exorcising Statistical Demons from Language Models with Anti-Models of Negative Data
Oct 22, 2020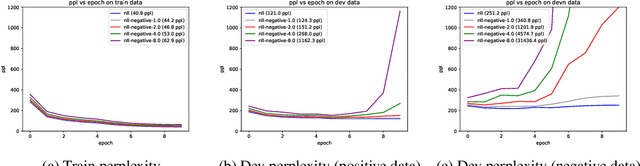
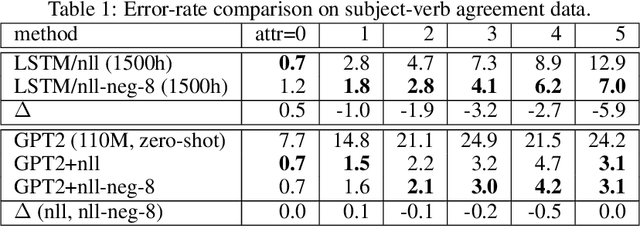
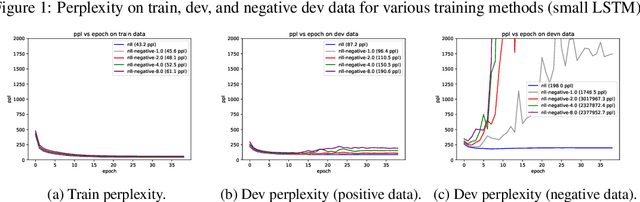
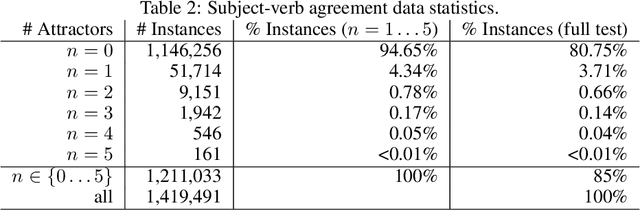
It's been said that "Language Models are Unsupervised Multitask Learners." Indeed, self-supervised language models trained on "positive" examples of English text generalize in desirable ways to many natural language tasks. But if such models can stray so far from an initial self-supervision objective, a wayward model might generalize in undesirable ways too, say to nonsensical "negative" examples of unnatural language. A key question in this work is: do language models trained on (positive) training data also generalize to (negative) test data? We use this question as a contrivance to assess the extent to which language models learn undesirable properties of text, such as n-grams, that might interfere with the learning of more desirable properties of text, such as syntax. We find that within a model family, as the number of parameters, training epochs, and data set size increase, so does a model's ability to generalize to negative n-gram data, indicating standard self-supervision generalizes too far. We propose a form of inductive bias that attenuates such undesirable signals with negative data distributions automatically learned from positive data. We apply the method to remove n-gram signals from LSTMs and find that doing so causes them to favor syntactic signals, as demonstrated by large error reductions (up to 46% on the hardest cases) on a syntactic subject-verb agreement task.
Learning Dynamic Feature Selection for Fast Sequential Prediction
May 22, 2015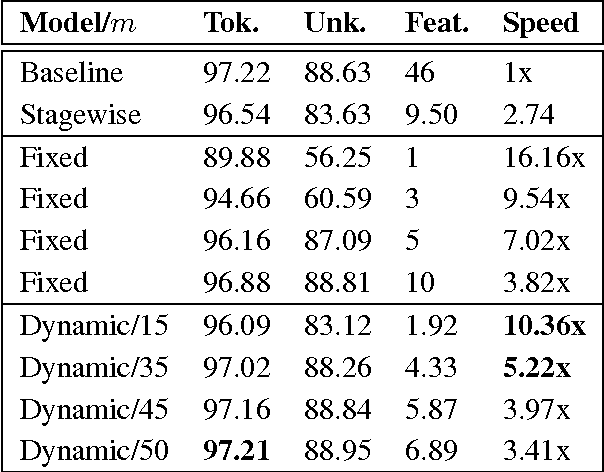
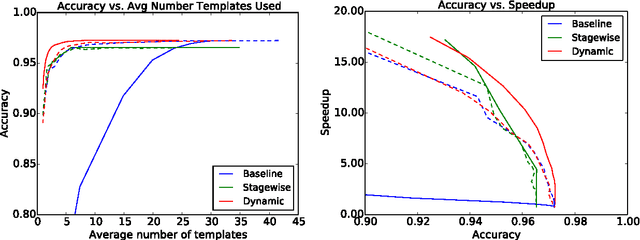

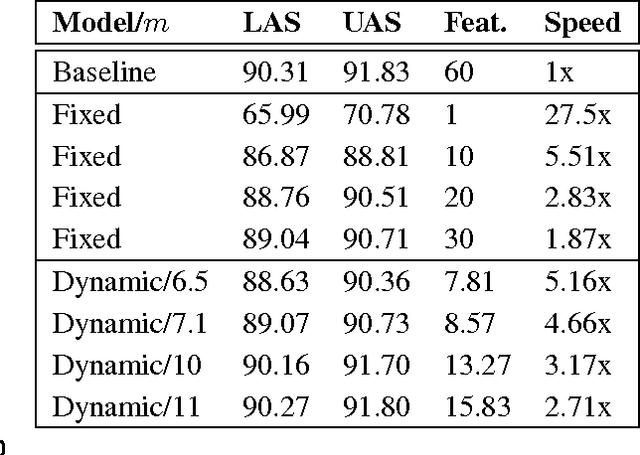
We present paired learning and inference algorithms for significantly reducing computation and increasing speed of the vector dot products in the classifiers that are at the heart of many NLP components. This is accomplished by partitioning the features into a sequence of templates which are ordered such that high confidence can often be reached using only a small fraction of all features. Parameter estimation is arranged to maximize accuracy and early confidence in this sequence. Our approach is simpler and better suited to NLP than other related cascade methods. We present experiments in left-to-right part-of-speech tagging, named entity recognition, and transition-based dependency parsing. On the typical benchmarking datasets we can preserve POS tagging accuracy above 97% and parsing LAS above 88.5% both with over a five-fold reduction in run-time, and NER F1 above 88 with more than 2x increase in speed.