 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Clarification and Correction Dialogues about Data-Centric Tasks -- A Teacher-Student Approach
Paper and Code
Mar 18, 2025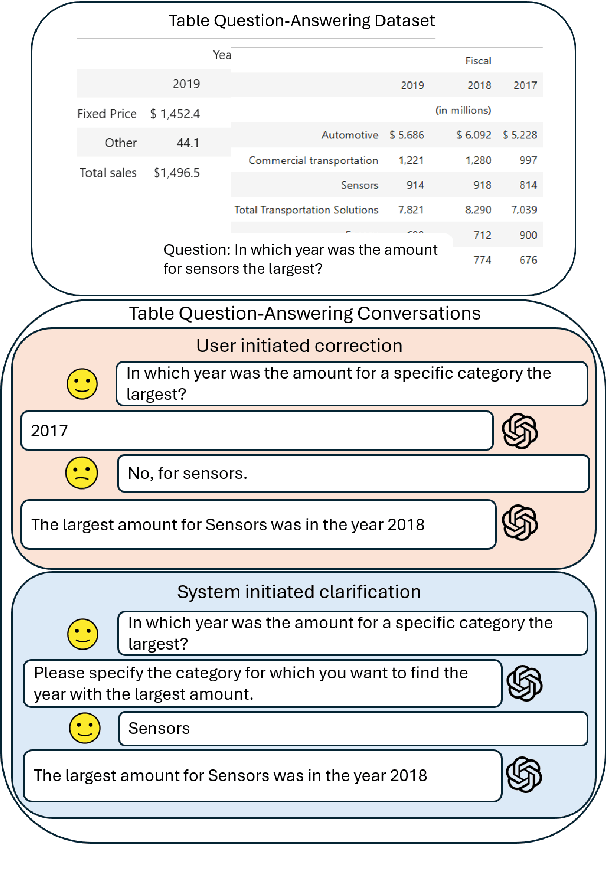
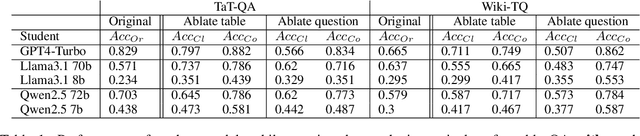
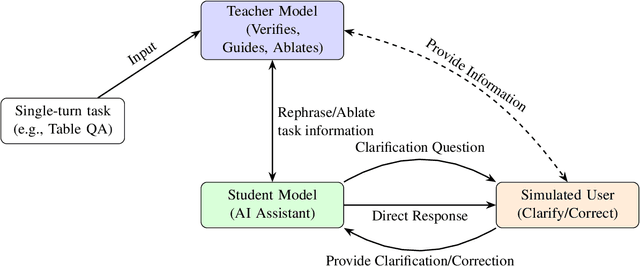
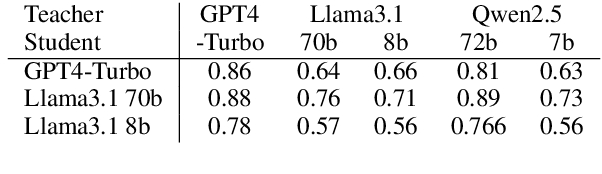
Real dialogues with AI assistants for solving data-centric tasks often follow dynamic, unpredictable paths due to imperfect information provided by the user or in the data, which must be caught and handled. Developing datasets which capture such user-AI interactions is difficult and time-consuming. In this work, we develop a novel framework for synthetically generating controlled, multi-turn conversations between a user and AI assistant for the task of table-based question answering, which can be generated from an existing dataset with fully specified table QA examples for any target domain. Each conversation aims to solve a table-based reasoning question through collaborative effort, modeling one of two real-world scenarios: (1) an AI-initiated clarification, or (2) a user-initiated correction. Critically, we employ a strong teacher LLM to verify the correctness of our synthetic conversations, ensuring high quality. We demonstrate synthetic datasets generated from TAT-QA and WikiTableQuestions as benchmarks of frontier LLMs. We find that even larger models struggle to effectively issuing clarification questions and accurately integrate user feedback for corrections.