 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitCab: Lightweight Calibration of Language Models on Outputs of Varied Lengths
Paper and Code
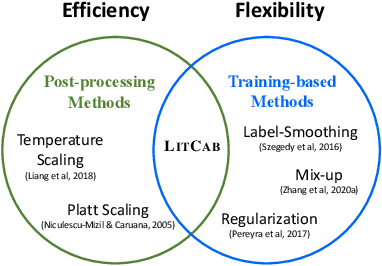
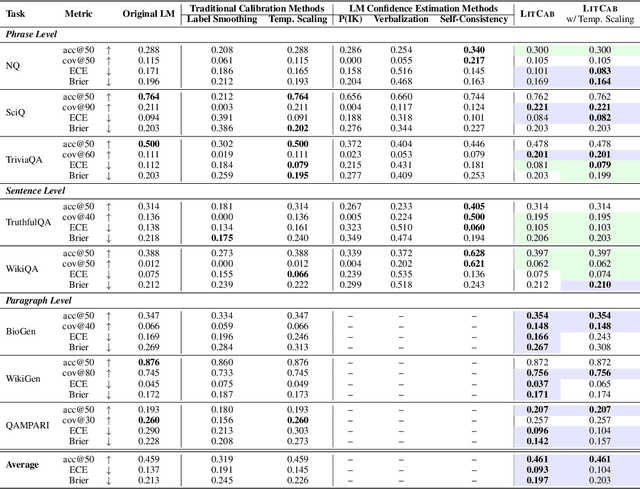
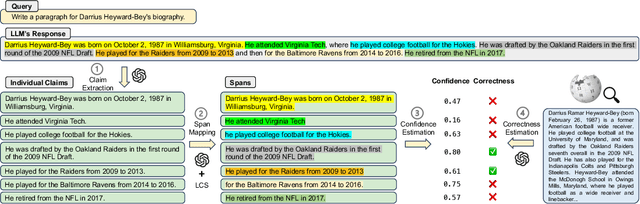

A model is considered well-calibrated when its probability estimate aligns with the actual likelihood of the output being correct. Calibrating language models (LMs) is crucial, as it plays a vital role in detecting and mitigating hallucinations, a common issue of LMs, as well as building more trustworthy models. Yet, popular neural model calibration techniques are not well-suited for LMs due to their lack of flexibility in discerning answer correctness and their high computational costs. For instance, post-processing methods like temperature scaling are often unable to reorder the candidate generations. Moreover, training-based methods require finetuning the entire model, which is impractical due to the increasing sizes of modern LMs. In this paper, we present LitCab, a lightweight calibration mechanism consisting of a single linear layer taking the input text representation and manipulateing the LM output logits. LitCab improves model calibration by only adding < 2% of the original model parameters. For evaluation, we construct CaT, a benchmark consisting of 7 text generation tasks, covering responses ranging from short phrases to paragraphs. We test LitCab with Llama2-7B, where it improves calibration across all tasks, by reducing the average ECE score by 20%. We further conduct a comprehensive evaluation with 7 popular open-sourced LMs from GPT and LLaMA families, yielding the following key findings: (1) Larger models within the same family exhibit better calibration on tasks with short generation tasks, but not necessarily for longer ones. (2) GPT-family models show superior calibration compared to LLaMA, Llama2 and Vicuna models despite having much fewer parameters. (3) Finetuning pretrained model (e.g., LLaMA) with samples of limited purpose (e.g., conversations) may lead to worse calibration, highlighting the importance of finetuning setups for calibrating LMs.