 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval or Global Context Understanding? On Many-Shot In-Context Learning for Long-Context Evaluation
Paper and Code
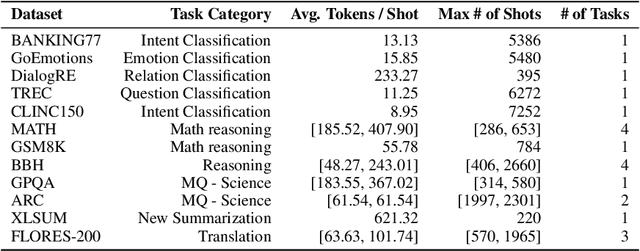
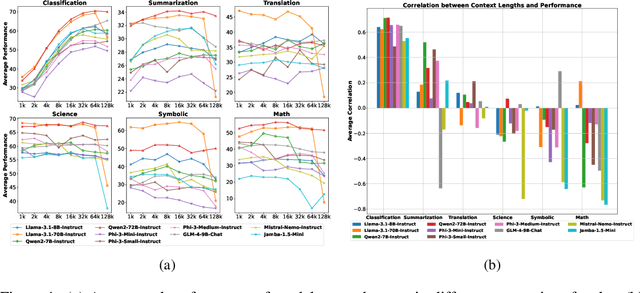
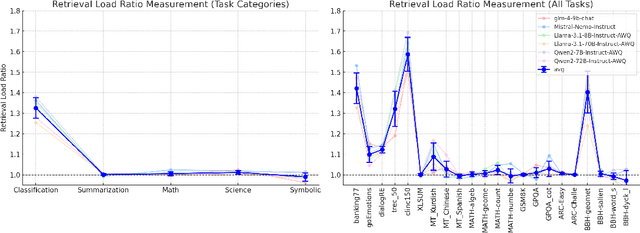
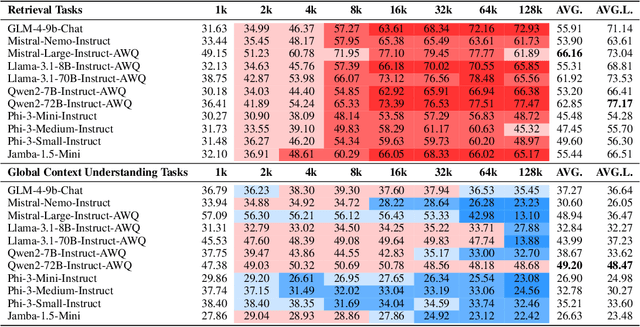
Language models (LMs) have demonstrated an improved capacity to handle long-context information, yet existing long-context benchmarks primarily measure LMs' retrieval abilities with extended inputs, e.g., pinpointing a short phrase from long-form text. Therefore, they may fall short when evaluating models' global context understanding capacity, such as synthesizing and reasoning over content across input to generate the response. In this paper, we study long-context language model (LCLM) evaluation through many-shot in-context learning (ICL). Concretely, we identify the skills each ICL task requires, and examine models' long-context capabilities on them. We first ask: What types of ICL tasks benefit from additional demonstrations, and are these tasks effective at evaluating LCLMs? We find that classification and summarization tasks show notable performance improvements with additional demonstrations, while translation and reasoning tasks do not exhibit clear trends. This suggests the classification tasks predominantly test models' retrieval skills. Next, we ask: To what extent does each task require retrieval skills versus global context understanding from LCLMs? We develop metrics to categorize ICL tasks into two groups: (i) retrieval tasks that require strong retrieval ability to pinpoint relevant examples, and (ii) global context understanding tasks that necessitate a deeper comprehension of the full input. We find that not all datasets can effectively evaluate these long-context capabilities. To address this gap, we introduce a new many-shot ICL benchmark, MANYICLBENCH, designed to characterize LCLMs' retrieval and global context understanding capabilities separately. Benchmarking 11 open-weight LCLMs with MANYICLBENCH, we find that while state-of-the-art models perform well in retrieval tasks up to 64k tokens, many show significant drops in global context tasks at just 16k tokens.