 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Machine Learning for Static Panel Models with Fixed Effects
Dec 19, 2023



Machine Learning (ML) algorithms are powerful data-driven tools for approximating highdimensional or non-linear nuisance functions which are useful in practice because the true functional form of the predictors is ex-ante unknown. In this paper, we develop estimators of policy interventions from panel data which allow for non-linear effects of the confounding regressors, and investigate the performance of these estimators using three well-known ML algorithms, specifically, LASSO, classification and regression trees, and random forests. We use Double Machine Learning (DML) (Chernozhukov et al., 2018) for the estimation of causal effects of homogeneous treatments with unobserved individual heterogeneity (fixed effects) and no unobserved confounding by extending Robinson (1988)'s partially linear regression model. We develop three alternative approaches for handling unobserved individual heterogeneity based on extending the within-group estimator, first-difference estimator, and correlated random effect estimator (Mundlak, 1978) for non-linear models. Using Monte Carlo simulations, we find that conventional least squares estimators can perform well even if the data generating process is nonlinear, but there are substantial performance gains in terms of bias reduction under a process where the true effect of the regressors is non-linear and discontinuous. However, for the same scenarios, we also find - despite extensive hyperparameter tuning - inference to be problematic for both tree-based learners because these lead to highly non-normal estimator distributions and the estimator variance being severely under-estimated. This contradicts the performance of trees in other circumstances and requires further investigation. Finally, we provide an illustrative example of DML for observational panel data showing the impact of the introduction of the national minimum wage in the UK.
Robustness of Algorithms for Causal Structure Learning to Hyperparameter Choice
Oct 27, 2023



Hyperparameters play a critical role in machine learning. Hyperparameter tuning can make the difference between state-of-the-art and poor prediction performance for any algorithm, but it is particularly challenging for structure learning due to its unsupervised nature. As a result, hyperparameter tuning is often neglected in favour of using the default values provided by a particular implementation of an algorithm. While there have been numerous studies on performance evaluation of causal discovery algorithms, how hyperparameters affect individual algorithms, as well as the choice of the best algorithm for a specific problem, has not been studied in depth before. This work addresses this gap by investigating the influence of hyperparameters on causal structure learning tasks. Specifically, we perform an empirical evaluation of hyperparameter selection for some seminal learning algorithms on datasets of varying levels of complexity. We find that, while the choice of algorithm remains crucial to obtaining state-of-the-art performance, hyperparameter selection in ensemble settings strongly influences the choice of algorithm, in that a poor choice of hyperparameters can lead to analysts using algorithms which do not give state-of-the-art performance for their data.
Hyperparameter Tuning and Model Evaluation in Causal Effect Estimation
Mar 02, 2023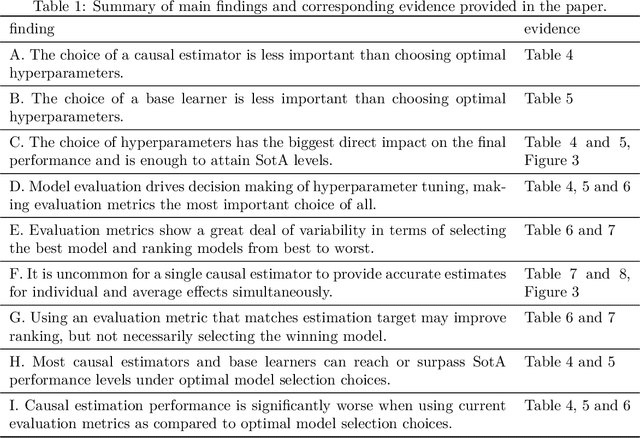
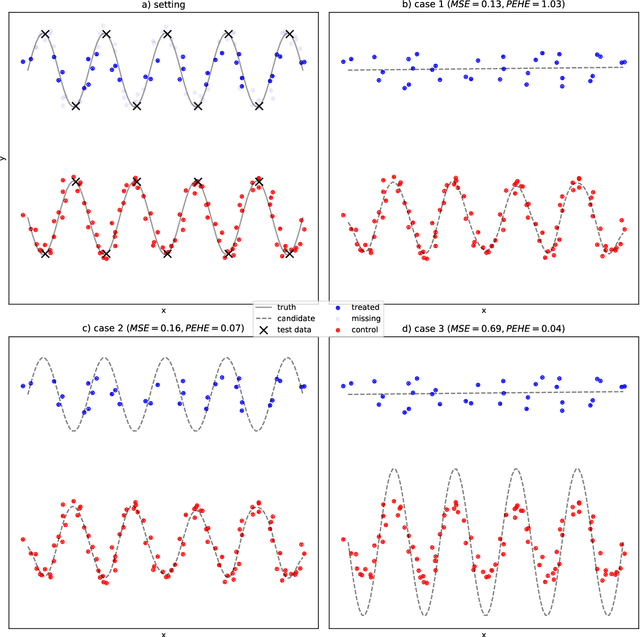
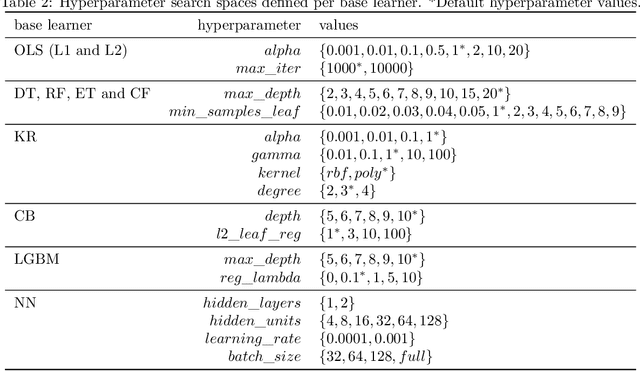
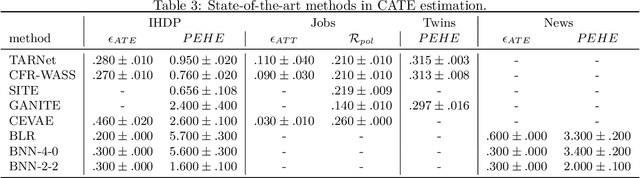
The performance of most causal effect estimators relies on accurate predictions of high-dimensional non-linear functions of the observed data. The remarkable flexibility of modern Machine Learning (ML) methods is perfectly suited to this task. However, data-driven hyperparameter tuning of ML methods requires effective model evaluation to avoid large errors in causal estimates, a task made more challenging because causal inference involves unavailable counterfactuals. Multiple performance-validation metrics have recently been proposed such that practitioners now not only have to make complex decisions about which causal estimators, ML learners and hyperparameters to choose, but also about which evaluation metric to use. This paper, motivated by unclear recommendations, investigates the interplay between the four different aspects of model evaluation for causal effect estimation. We develop a comprehensive experimental setup that involves many commonly used causal estimators, ML methods and evaluation approaches and apply it to four well-known causal inference benchmark datasets. Our results suggest that optimal hyperparameter tuning of ML learners is enough to reach state-of-the-art performance in effect estimation, regardless of estimators and learners. We conclude that most causal estimators are roughly equivalent in performance if tuned thoroughly enough. We also find hyperparameter tuning and model evaluation are much more important than causal estimators and ML methods. Finally, from the significant gap we find in estimation performance of popular evaluation metrics compared with optimal model selection choices, we call for more research into causal model evaluation to unlock the optimum performance not currently being delivered even by state-of-the-art procedures.
Undersmoothing Causal Estimators with Generative Trees
Mar 16, 2022



Inferring individualised treatment effects from observational data can unlock the potential for targeted interventions. It is, however, hard to infer these effects from observational data. One major problem that can arise is covariate shift where the data (outcome) conditional distribution remains the same but the covariate (input) distribution changes between the training and test set. In an observational data setting, this problem is materialised in control and treated units coming from different distributions. A common solution is to augment learning methods through reweighing schemes (e.g. propensity scores). These are needed due to model misspecification, but might hurt performance in the individual case. In this paper, we explore a novel generative tree based approach that tackles model misspecification directly, helping downstream estimators achieve better robustness. We show empirically that the choice of model class can indeed significantly affect the final performance and that reweighing methods can struggle in individualised effect estimation. Our proposed approach is competitive with reweighing methods on average treatment effects while performing significantly better on individualised treatment effects.