 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Reasoning! When Multimodal LLMs with Chain-of-Thought Reasoning Meets Adversarial Images
Feb 22, 2024


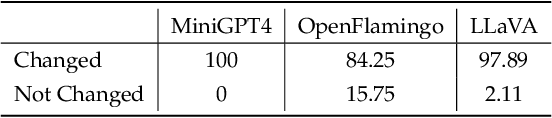
Recently, Multimodal LLMs (MLLMs) have shown a great ability to understand images. However, like traditional vision models, they are still vulnerable to adversarial images. Meanwhile, Chain-of-Thought (CoT) reasoning has been widely explored on MLLMs, which not only improves model's performance, but also enhances model's explainability by giving intermediate reasoning steps. Nevertheless, there is still a lack of study regarding MLLMs' adversarial robustness with CoT and an understanding of what the rationale looks like when MLLMs infer wrong answers with adversarial images. Our research evaluates the adversarial robustness of MLLMs when employing CoT reasoning, finding that CoT marginally improves adversarial robustness against existing attack methods. Moreover, we introduce a novel stop-reasoning attack technique that effectively bypasses the CoT-induced robustness enhancements. Finally, we demonstrate the alterations in CoT reasoning when MLLMs confront adversarial images, shedding light on their reasoning process under adversarial attacks.