 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Reasoning! When Multimodal LLMs with Chain-of-Thought Reasoning Meets Adversarial Images
Feb 22, 2024


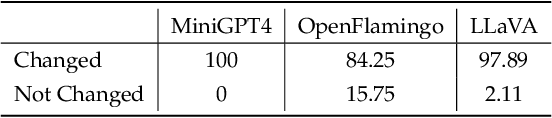
Recently, Multimodal LLMs (MLLMs) have shown a great ability to understand images. However, like traditional vision models, they are still vulnerable to adversarial images. Meanwhile, Chain-of-Thought (CoT) reasoning has been widely explored on MLLMs, which not only improves model's performance, but also enhances model's explainability by giving intermediate reasoning steps. Nevertheless, there is still a lack of study regarding MLLMs' adversarial robustness with CoT and an understanding of what the rationale looks like when MLLMs infer wrong answers with adversarial images. Our research evaluates the adversarial robustness of MLLMs when employing CoT reasoning, finding that CoT marginally improves adversarial robustness against existing attack methods. Moreover, we introduce a novel stop-reasoning attack technique that effectively bypasses the CoT-induced robustness enhancements. Finally, we demonstrate the alterations in CoT reasoning when MLLMs confront adversarial images, shedding light on their reasoning process under adversarial attacks.
HRHD-HK: A benchmark dataset of high-rise and high-density urban scenes for 3D semantic segmentation of photogrammetric point clouds
Jul 16, 2023



Many existing 3D semantic segmentation methods, deep learning in computer vision notably, claimed to achieve desired results on urban point clouds, in which the city objects are too many and diverse for people to judge qualitatively. Thus, it is significant to assess these methods quantitatively in diversified real-world urban scenes, encompassing high-rise, low-rise, high-density, and low-density urban areas. However, existing public benchmark datasets primarily represent low-rise scenes from European cities and cannot assess the methods comprehensively. This paper presents a benchmark dataset of high-rise urban point clouds, namely High-Rise, High-Density urban scenes of Hong Kong (HRHD-HK), which has been vacant for a long time. HRHD-HK arranged in 150 tiles contains 273 million colorful photogrammetric 3D points from diverse urban settings. The semantic labels of HRHD-HK include building, vegetation, road, waterbody, facility, terrain, and vehicle. To the best of our knowledge, HRHD-HK is the first photogrammetric dataset that focuses on HRHD urban areas. This paper also comprehensively evaluates eight popular semantic segmentation methods on the HRHD-HK dataset. Experimental results confirmed plenty of room for enhancing the current 3D semantic segmentation of point clouds, especially for city objects with small volumes. Our dataset is publicly available at: https://github.com/LuZaiJiaoXiaL/HRHD-HK.
FloorPP-Net: Reconstructing Floor Plans using Point Pillars for Scan-to-BIM
Jun 20, 2021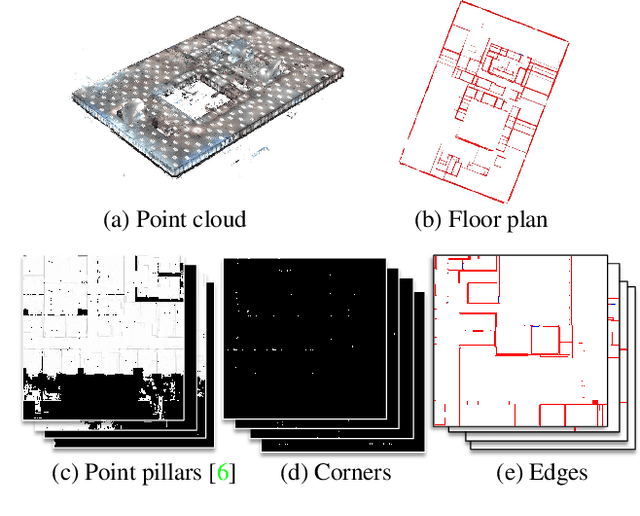


This paper presents a deep learning-based point cloud processing method named FloorPP-Net for the task of Scan-to-BIM (building information model). FloorPP-Net first converts the input point cloud of a building story into point pillars (PP), then predicts the corners and edges to output the floor plan. Altogether, FloorPP-Net establishes an end-to-end supervised learning framework for the Scan-to-Floor-Plan (Scan2FP) task. In the 1st International Scan-to-BIM Challenge held in conjunction with CVPR 2021, FloorPP-Net was ranked the second runner-up in the floor plan reconstruction track. Future work includes general edge proposals, 2D plan regularization, and 3D BIM reconstruction.