 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-Person: Text-Based Person Retrieval with Scene-aware Re-ranking
May 30, 2025Text-based person retrieval aims to identify a target individual from a gallery of images based on a natural language description. It presents a significant challenge due to the complexity of real-world scenes and the ambiguity of appearance-related descriptions. Existing methods primarily emphasize appearance-based cross-modal retrieval, often neglecting the contextual information embedded within the scene, which can offer valuable complementary insights for retrieval. To address this, we introduce SCENEPERSON-13W, a large-scale dataset featuring over 100,000 scenes with rich annotations covering both pedestrian appearance and environmental cues. Based on this, we propose SA-Person, a two-stage retrieval framework. In the first stage, it performs discriminative appearance grounding by aligning textual cues with pedestrian-specific regions. In the second stage, it introduces SceneRanker, a training-free, scene-aware re-ranking method leveraging multimodal large language models to jointly reason over pedestrian appearance and the global scene context. Experiments on SCENEPERSON-13W validate the effectiveness of our framework in challenging scene-level retrieval scenarios. The code and dataset will be made publicly available.
Semi-supervised Text-based Person Search
Apr 28, 2024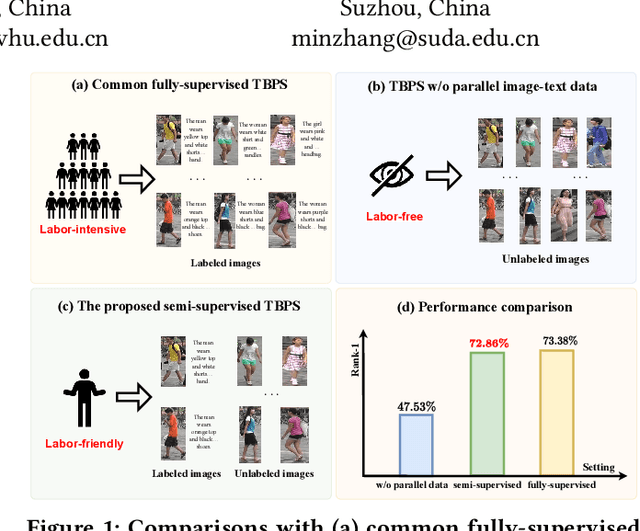
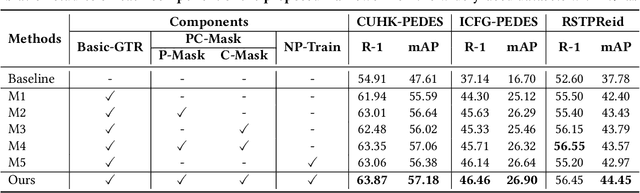
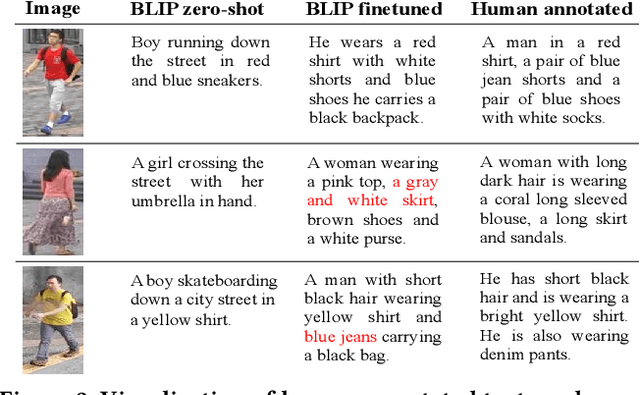
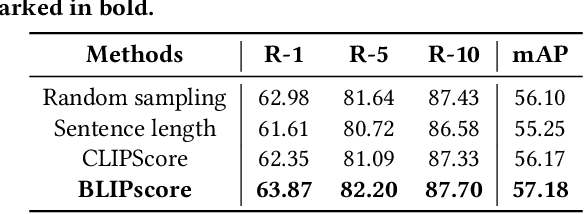
Text-based person search (TBPS) aims to retrieve images of a specific person from a large image gallery based on a natural language description. Existing methods rely on massive annotated image-text data to achieve satisfactory performance in fully-supervised learning. It poses a significant challenge in practice, as acquiring person images from surveillance videos is relatively easy, while obtaining annotated texts is challenging. The paper undertakes a pioneering initiative to explore TBPS under the semi-supervised setting, where only a limited number of person images are annotated with textual descriptions while the majority of images lack annotations. We present a two-stage basic solution based on generation-then-retrieval for semi-supervised TBPS. The generation stage enriches annotated data by applying an image captioning model to generate pseudo-texts for unannotated images. Later, the retrieval stage performs fully-supervised retrieval learning using the augmented data. Significantly, considering the noise interference of the pseudo-texts on retrieval learning, we propose a noise-robust retrieval framework that enhances the ability of the retrieval model to handle noisy data. The framework integrates two key strategies: Hybrid Patch-Channel Masking (PC-Mask) to refine the model architecture, and Noise-Guided Progressive Training (NP-Train) to enhance the training process. PC-Mask performs masking on the input data at both the patch-level and the channel-level to prevent overfitting noisy supervision. NP-Train introduces a progressive training schedule based on the noise level of pseudo-texts to facilitate noise-robust learning. Extensive experiments on multiple TBPS benchmarks show that the proposed framework achieves promising performance under the semi-supervised setting.
RaSa: Relation and Sensitivity Aware Representation Learning for Text-based Person Search
May 23, 2023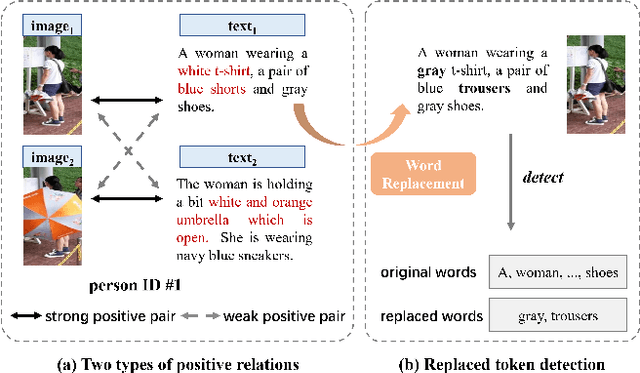
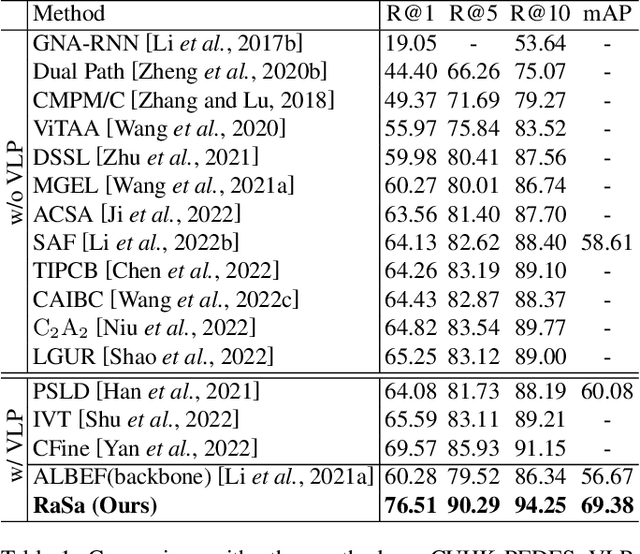
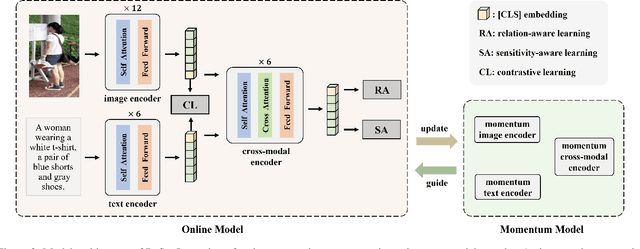
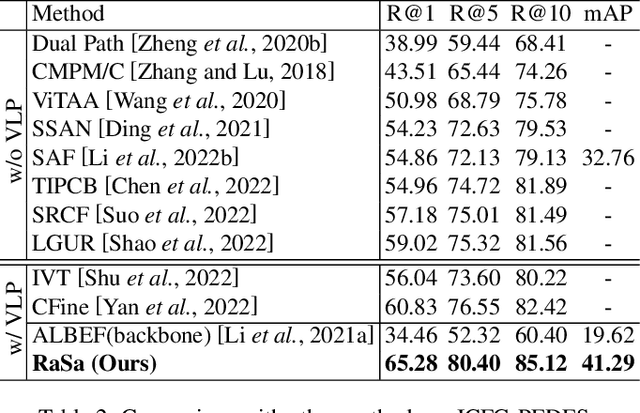
Text-based person search aims to retrieve the specified person images given a textual description. The key to tackling such a challenging task is to learn powerful multi-modal representations. Towards this, we propose a Relation and Sensitivity aware representation learning method (RaSa), including two novel tasks: Relation-Aware learning (RA) and Sensitivity-Aware learning (SA). For one thing, existing methods cluster representations of all positive pairs without distinction and overlook the noise problem caused by the weak positive pairs where the text and the paired image have noise correspondences, thus leading to overfitting learning. RA offsets the overfitting risk by introducing a novel positive relation detection task (i.e., learning to distinguish strong and weak positive pairs). For another thing, learning invariant representation under data augmentation (i.e., being insensitive to some transformations) is a general practice for improving representation's robustness in existing methods. Beyond that, we encourage the representation to perceive the sensitive transformation by SA (i.e., learning to detect the replaced words), thus promoting the representation's robustness. Experiments demonstrate that RaSa outperforms existing state-of-the-art methods by 6.94%, 4.45% and 15.35% in terms of Rank@1 on CUHK-PEDES, ICFG-PEDES and RSTPReid datasets, respectively. Code is available at: https://github.com/Flame-Chasers/RaSa.