 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Occurrence-Balanced Mixup for Long-tailed Recognition
Oct 11, 2021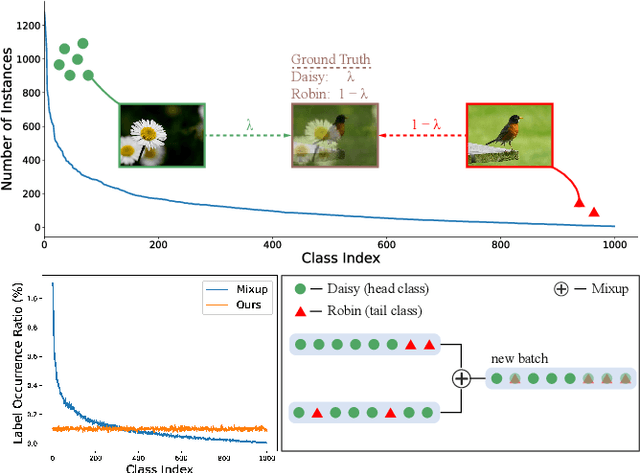
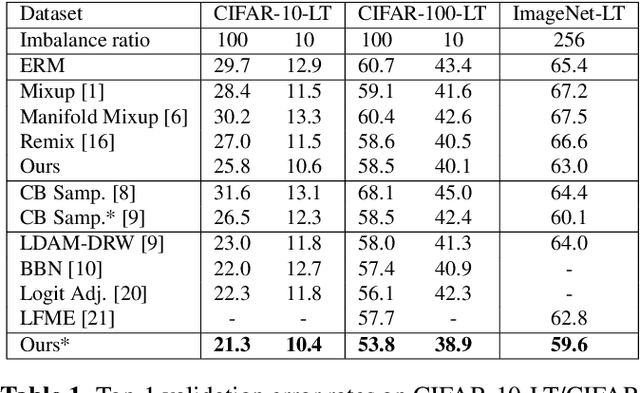
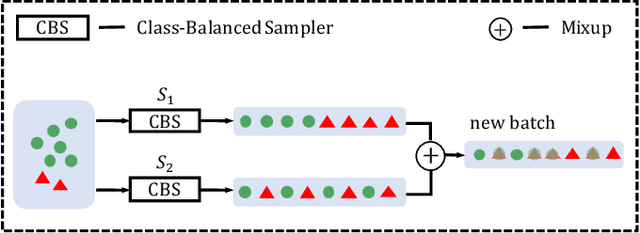
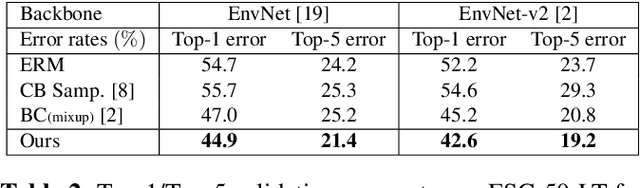
Mixup is a popular data augmentation method, with many variants subsequently proposed. These methods mainly create new examples via convex combination of random data pairs and their corresponding one-hot labels. However, most of them adhere to a random sampling and mixing strategy, without considering the frequency of label occurrence in the mixing process. When applying mixup to long-tailed data, a label suppression issue arises, where the frequency of label occurrence for each class is imbalanced and most of the new examples will be completely or partially assigned with head labels. The suppression effect may further aggravate the problem of data imbalance and lead to a poor performance on tail classes. To address this problem, we propose Label-Occurrence-Balanced Mixup to augment data while keeping the label occurrence for each class statistically balanced. In a word, we employ two independent class-balanced samplers to select data pairs and mix them to generate new data. We test our method on several long-tailed vision and sound recognition benchmarks. Experimental results show that our method significantly promotes the adaptability of mixup method to imbalanced data and achieves superior performance compared with state-of-the-art long-tailed learning methods.
Balanced Knowledge Distillation for Long-tailed Learning
Apr 21, 2021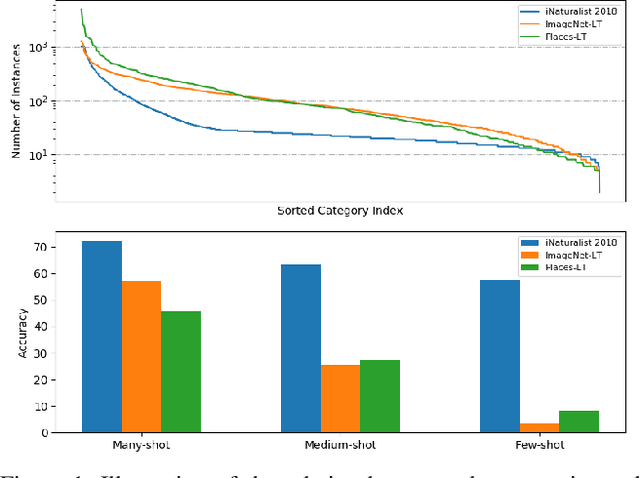
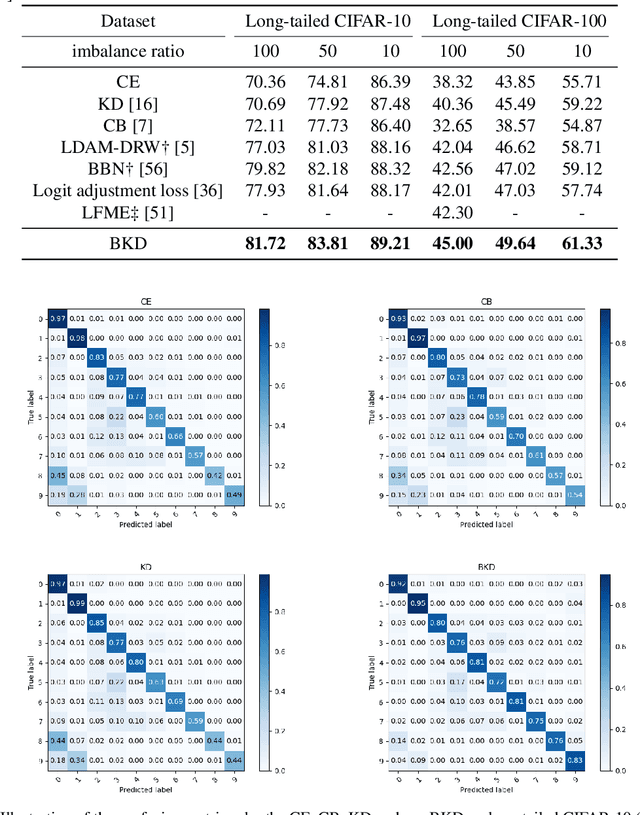
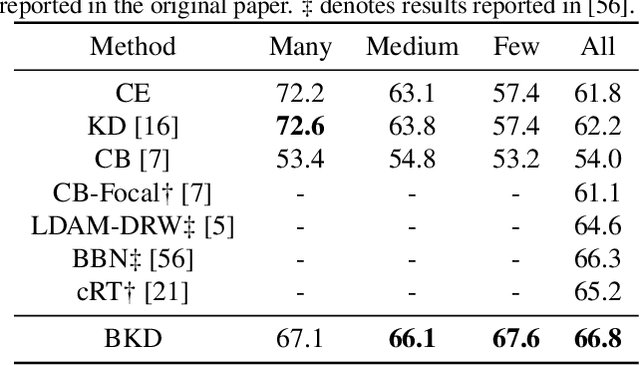
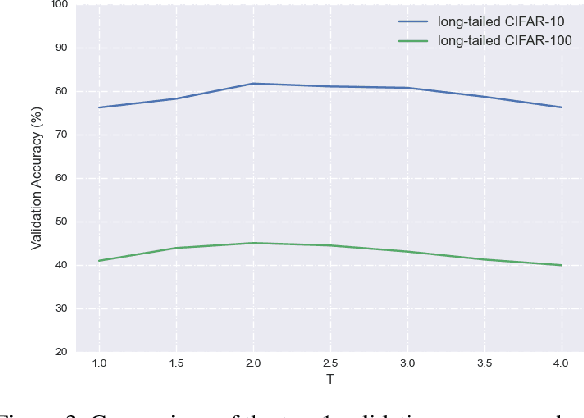
Deep models trained on long-tailed datasets exhibit unsatisfactory performance on tail classes. Existing methods usually modify the classification loss to increase the learning focus on tail classes, which unexpectedly sacrifice the performance on head classes. In fact, this scheme leads to a contradiction between the two goals of long-tailed learning, i.e., learning generalizable representations and facilitating learning for tail classes. In this work, we explore knowledge distillation in long-tailed scenarios and propose a novel distillation framework, named Balanced Knowledge Distillation (BKD), to disentangle the contradiction between the two goals and achieve both simultaneously. Specifically, given a vanilla teacher model, we train the student model by minimizing the combination of an instance-balanced classification loss and a class-balanced distillation loss. The former benefits from the sample diversity and learns generalizable representation, while the latter considers the class priors and facilitates learning mainly for tail classes. The student model trained with BKD obtains significant performance gain even compared with its teacher model. We conduct extensive experiments on several long-tailed benchmark datasets and demonstrate that the proposed BKD is an effective knowledge distillation framework in long-tailed scenarios, as well as a new state-of-the-art method for long-tailed learning. Code is available at https://github.com/EricZsy/BalancedKnowledgeDistillation .