 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transformation-Isomorphic Latent Space for Accurate Hand Pose Estimation
Feb 18, 2025Vision-based regression tasks, such as hand pose estimation, have achieved higher accuracy and faster convergence through representation learning. However, existing representation learning methods often encounter the following issues: the high semantic level of features extracted from images is inadequate for regressing low-level information, and the extracted features include task-irrelevant information, reducing their compactness and interfering with regression tasks. To address these challenges, we propose TI-Net, a highly versatile visual Network backbone designed to construct a Transformation Isomorphic latent space. Specifically, we employ linear transformations to model geometric transformations in the latent space and ensure that {\rm TI-Net} aligns them with those in the image space. This ensures that the latent features capture compact, low-level information beneficial for pose estimation tasks. We evaluated TI-Net on the hand pose estimation task to demonstrate the network's superiority. On the DexYCB dataset, TI-Net achieved a 10% improvement in the PA-MPJPE metric compared to specialized state-of-the-art (SOTA) hand pose estimation methods. Our code will be released in the future.
Spatial-Temporal Gating-Adjacency GCN for Human Motion Prediction
Mar 03, 2022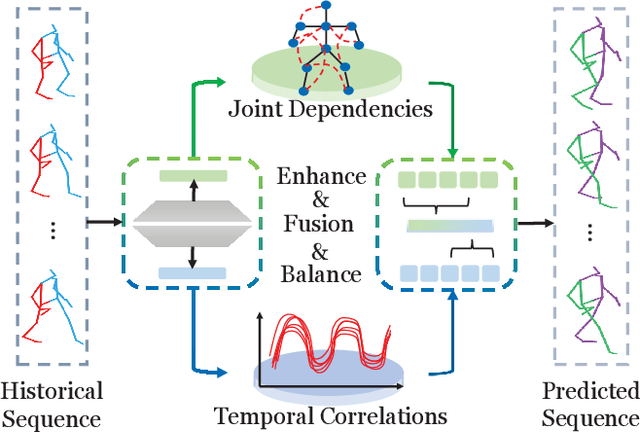
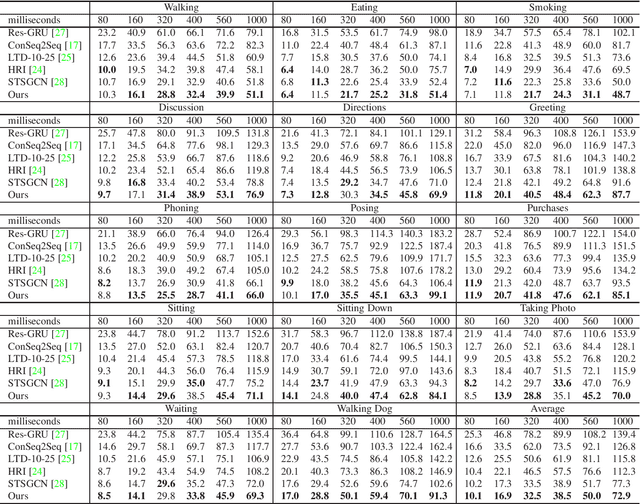
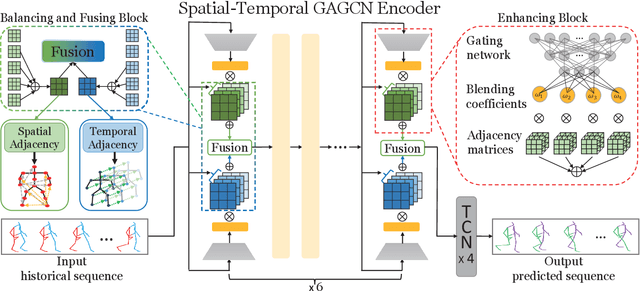
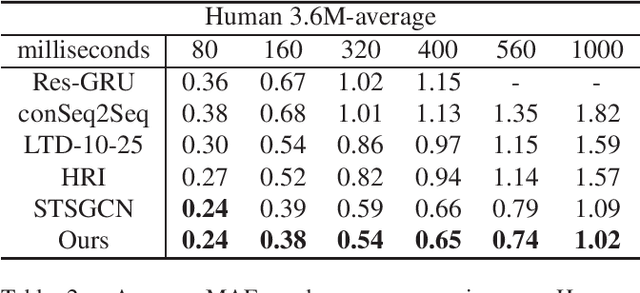
Predicting future motion based on historical motion sequence is a fundamental problem in computer vision, and it has wide applications in autonomous driving and robotics. Some recent works have shown that Graph Convolutional Networks(GCN) are instrumental in modeling the relationship between different joints. However, considering the variants and diverse action types in human motion data, the cross-dependency of the spatial-temporal relationships will be difficult to depict due to the decoupled modeling strategy, which may also exacerbate the problem of insufficient generalization. Therefore, we propose the Spatial-Temporal Gating-Adjacency GCN(GAGCN) to learn the complex spatial-temporal dependencies over diverse action types. Specifically, we adopt gating networks to enhance the generalization of GCN via the trainable adaptive adjacency matrix obtained by blending the candidate spatial-temporal adjacency matrices. Moreover, GAGCN addresses the cross-dependency of space and time by balancing the weights of spatial-temporal modeling and fusing the decoupled spatial-temporal features. Extensive experiments on Human 3.6M, AMASS, and 3DPW demonstrate that GAGCN achieves state-of-the-art performance in both short-term and long-term predictions. Our code will be released in the future.