 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-TalkEmo: Learning to Synthesize 3D Emotional Talking Head
Paper and Code
Apr 25, 2021
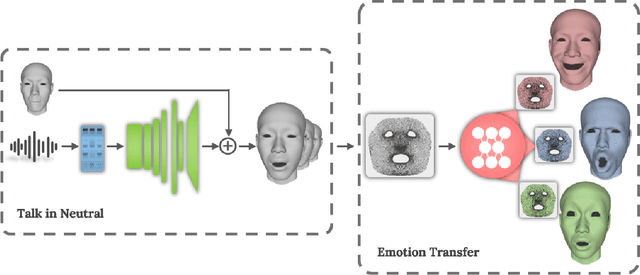


Impressive progress has been made in audio-driven 3D facial animation recently, but synthesizing 3D talking-head with rich emotion is still unsolved. This is due to the lack of 3D generative models and available 3D emotional dataset with synchronized audios. To address this, we introduce 3D-TalkEmo, a deep neural network that generates 3D talking head animation with various emotions. We also create a large 3D dataset with synchronized audios and videos, rich corpus, as well as various emotion states of different persons with the sophisticated 3D face reconstruction methods. In the emotion generation network, we propose a novel 3D face representation structure - geometry map by classical multi-dimensional scaling analysis. It maps the coordinates of vertices on a 3D face to a canonical image plane, while preserving the vertex-to-vertex geodesic distance metric in a least-square sense. This maintains the adjacency relationship of each vertex and holds the effective convolutional structure for the 3D facial surface. Taking a neutral 3D mesh and a speech signal as inputs, the 3D-TalkEmo is able to generate vivid facial animations. Moreover, it provides access to change the emotion state of the animated speaker. We present extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating the generated talking-heads of significantly higher quality compared to previous state-of-the-art methods.