 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPANet: Depth Potentiality-Aware Gated Attention Network for RGB-D Salient Object Detection
Paper and Code

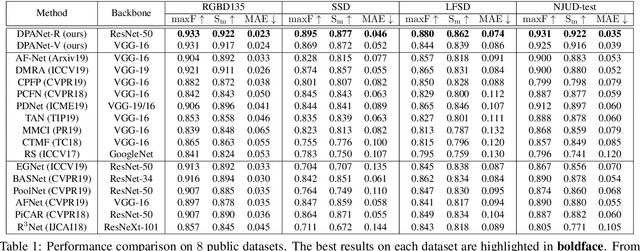

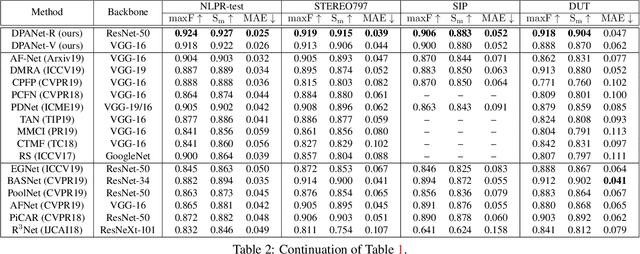
There are two main issues in RGB-D salient object detection: (1) how to effectively integrate the complementarity from the cross-modal RGB-D data; (2) how to prevent the contamination effect from the unreliable depth map. In fact, these two problems are linked and intertwined, but the previous methods tend to focus only on the first problem and ignore the consideration of depth map quality, which may yield the model fall into the sub-optimal state. In this paper, we address these two issues in a holistic model synergistically, and propose a novel network named DPANet to explicitly model the potentiality of the depth map and effectively integrate the cross-modal complementarity. By introducing the depth potentiality perception, the network can perceive the potentiality of depth information in a learning-based manner, and guide the fusion process of two modal data to prevent the contamination occurred. The gated multi-modality attention module in the fusion process exploits the attention mechanism with a gate controller to capture long-range dependencies from a cross-modal perspective. Experimental results compared with 15 state-of-the-art methods on 8 datasets demonstrate the validity of the proposed approach both quantitatively and qualitatively.