 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Learning
Paper and Code
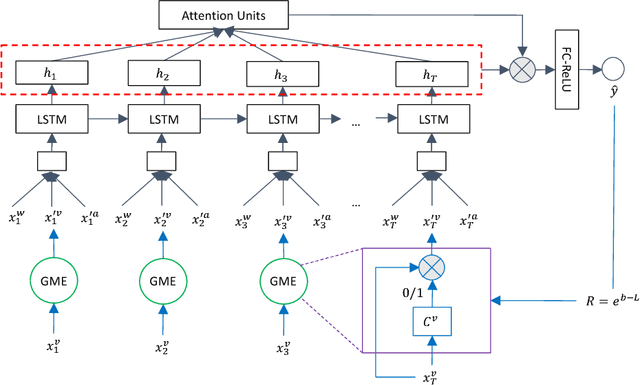
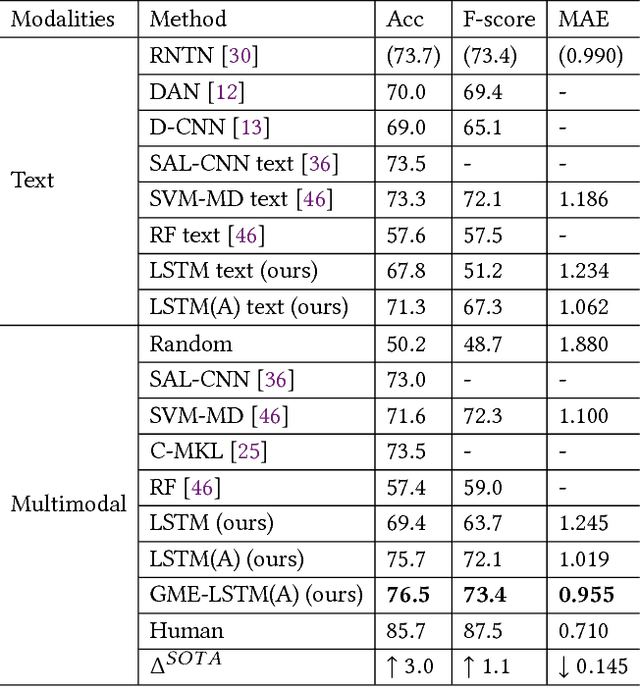

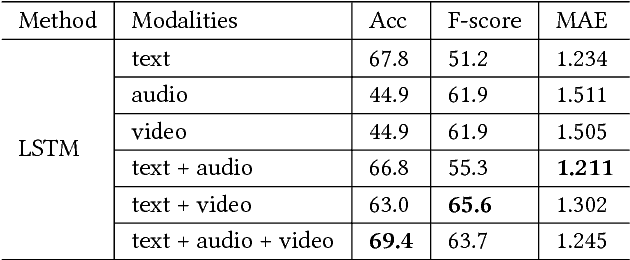
With the increasing popularity of video sharing websites such as YouTube and Facebook, multimodal sentiment analysis has received increasing attention from the scientific community. Contrary to previous works in multimodal sentiment analysis which focus on holistic information in speech segments such as bag of words representations and average facial expression intensity, we develop a novel deep architecture for multimodal sentiment analysis that performs modality fusion at the word level. In this paper, we propose the Gated Multimodal Embedding LSTM with Temporal Attention (GME-LSTM(A)) model that is composed of 2 modules. The Gated Multimodal Embedding alleviates the difficulties of fusion when there are noisy modalities. The LSTM with Temporal Attention performs word level fusion at a finer fusion resolution between input modalities and attends to the most important time steps. As a result, the GME-LSTM(A) is able to better model the multimodal structure of speech through time and perform better sentiment comprehension. We demonstrate the effectiveness of this approach on the publicly-available Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis (CMU-MOSI) dataset by achieving state-of-the-art sentiment classification and regression results. Qualitative analysis on our model emphasizes the importance of the Temporal Attention Layer in sentiment prediction because the additional acoustic and visual modalities are noisy. We also demonstrate the effectiveness of the Gated Multimodal Embedding in selectively filtering these noisy modalities out. Our results and analysis open new areas in the study of sentiment analysis in human communication and provide new models for multimodal fusion.