 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Modeling for Human Motion Recovery Under Occlusions
Jan 23, 2026Human motion reconstruction from monocular videos is a fundamental challenge in computer vision, with broad applications in AR/VR, robotics, and digital content creation, but remains challenging under frequent occlusions in real-world settings. Existing regression-based methods are efficient but fragile to missing observations, while optimization- and diffusion-based approaches improve robustness at the cost of slow inference speed and heavy preprocessing steps. To address these limitations, we leverage recent advances in generative masked modeling and present MoRo: Masked Modeling for human motion Recovery under Occlusions. MoRo is an occlusion-robust, end-to-end generative framework that formulates motion reconstruction as a video-conditioned task, and efficiently recover human motion in a consistent global coordinate system from RGB videos. By masked modeling, MoRo naturally handles occlusions while enabling efficient, end-to-end inference. To overcome the scarcity of paired video-motion data, we design a cross-modality learning scheme that learns multi-modal priors from a set of heterogeneous datasets: (i) a trajectory-aware motion prior trained on MoCap datasets, (ii) an image-conditioned pose prior trained on image-pose datasets, capturing diverse per-frame poses, and (iii) a video-conditioned masked transformer that fuses motion and pose priors, finetuned on video-motion datasets to integrate visual cues with motion dynamics for robust inference. Extensive experiments on EgoBody and RICH demonstrate that MoRo substantially outperforms state-of-the-art methods in accuracy and motion realism under occlusions, while performing on-par in non-occluded scenarios. MoRo achieves real-time inference at 70 FPS on a single H200 GPU.
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Dec 15, 2023We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
EgoBody: Human Body Shape, Motion and Social Interactions from Head-Mounted Devices
Dec 14, 2021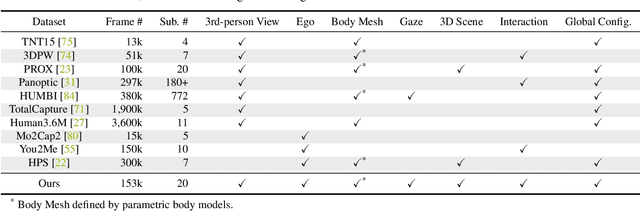
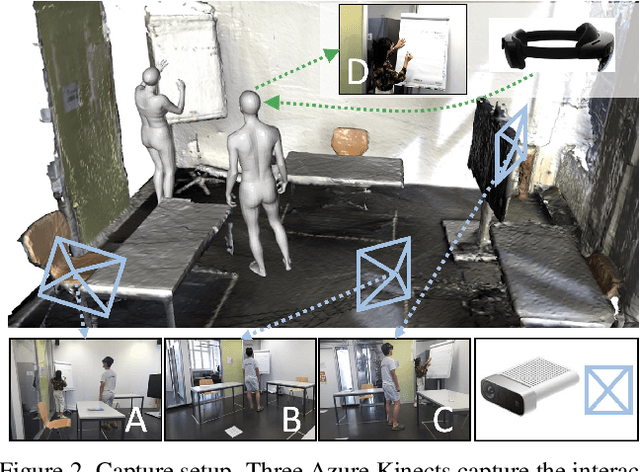


Understanding social interactions from first-person views is crucial for many applications, ranging from assistive robotics to AR/VR. A first step for reasoning about interactions is to understand human pose and shape. However, research in this area is currently hindered by the lack of data. Existing datasets are limited in terms of either size, annotations, ground-truth capture modalities or the diversity of interactions. We address this shortcoming by proposing EgoBody, a novel large-scale dataset for social interactions in complex 3D scenes. We employ Microsoft HoloLens2 headsets to record rich egocentric data streams (including RGB, depth, eye gaze, head and hand tracking). To obtain accurate 3D ground-truth, we calibrate the headset with a multi-Kinect rig and fit expressive SMPL-X body meshes to multi-view RGB-D frames, reconstructing 3D human poses and shapes relative to the scene. We collect 68 sequences, spanning diverse sociological interaction categories, and propose the first benchmark for 3D full-body pose and shape estimation from egocentric views. Our dataset and code will be available for research at https://sanweiliti.github.io/egobody/egobody.html.