 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS'21 Challenge on Billion-Scale Approximate Nearest Neighbor Search
May 08, 2022
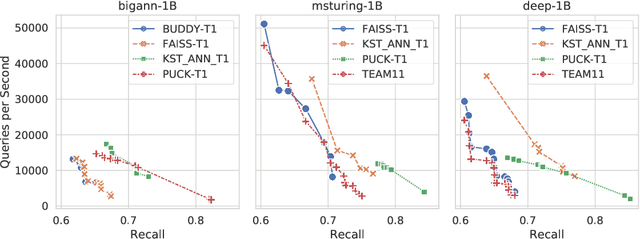
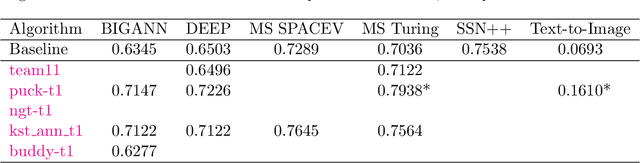
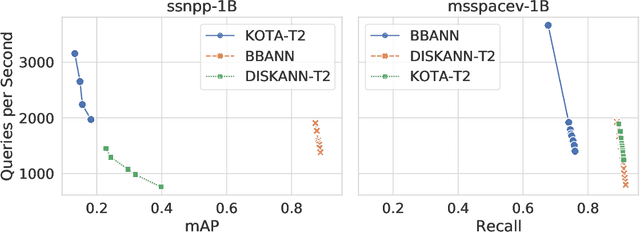
Despite the broad range of algorithms for Approximate Nearest Neighbor Search, most empirical evaluations of algorithms have focused on smaller datasets, typically of 1 million points~\citep{Benchmark}. However, deploying recent advances in embedding based techniques for search, recommendation and ranking at scale require ANNS indices at billion, trillion or larger scale. Barring a few recent papers, there is limited consensus on which algorithms are effective at this scale vis-\`a-vis their hardware cost. This competition compares ANNS algorithms at billion-scale by hardware cost, accuracy and performance. We set up an open source evaluation framework and leaderboards for both standardized and specialized hardware. The competition involves three tracks. The standard hardware track T1 evaluates algorithms on an Azure VM with limited DRAM, often the bottleneck in serving billion-scale indices, where the embedding data can be hundreds of GigaBytes in size. It uses FAISS~\citep{Faiss17} as the baseline. The standard hardware track T2 additional allows inexpensive SSDs in addition to the limited DRAM and uses DiskANN~\citep{DiskANN19} as the baseline. The specialized hardware track T3 allows any hardware configuration, and again uses FAISS as the baseline. We compiled six diverse billion-scale datasets, four newly released for this competition, that span a variety of modalities, data types, dimensions, deep learning models, distance functions and sources. The outcome of the competition was ranked leaderboards of algorithms in each track based on recall at a query throughput threshold. Additionally, for track T3, separate leaderboards were created based on recall as well as cost-normalized and power-normalized query throughput.
FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search
May 20, 2021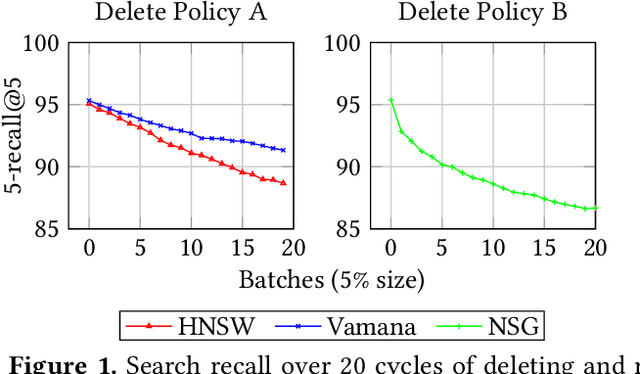
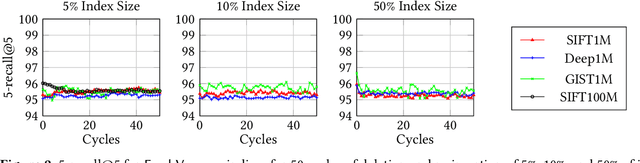
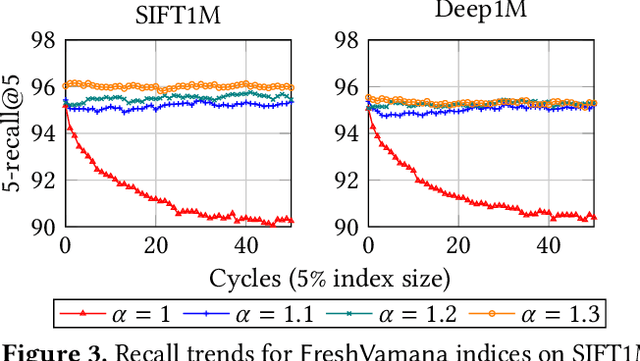
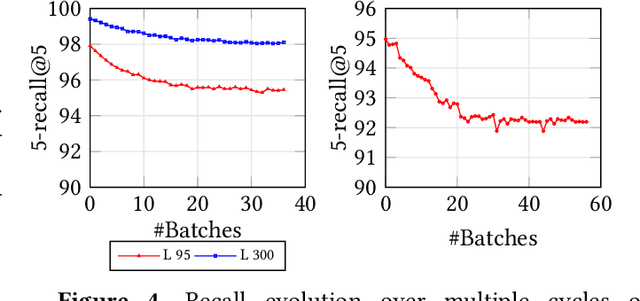
Approximate nearest neighbor search (ANNS) is a fundamental building block in information retrieval with graph-based indices being the current state-of-the-art and widely used in the industry. Recent advances in graph-based indices have made it possible to index and search billion-point datasets with high recall and millisecond-level latency on a single commodity machine with an SSD. However, existing graph algorithms for ANNS support only static indices that cannot reflect real-time changes to the corpus required by many key real-world scenarios (e.g. index of sentences in documents, email, or a news index). To overcome this drawback, the current industry practice for manifesting updates into such indices is to periodically re-build these indices, which can be prohibitively expensive. In this paper, we present the first graph-based ANNS index that reflects corpus updates into the index in real-time without compromising on search performance. Using update rules for this index, we design FreshDiskANN, a system that can index over a billion points on a workstation with an SSD and limited memory, and support thousands of concurrent real-time inserts, deletes and searches per second each, while retaining $>95\%$ 5-recall@5. This represents a 5-10x reduction in the cost of maintaining freshness in indices when compared to existing methods.