 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCB-Vision: A Multiscene RGB-Hyperspectral Benchmark Dataset of Printed Circuit Boards
Jan 12, 2024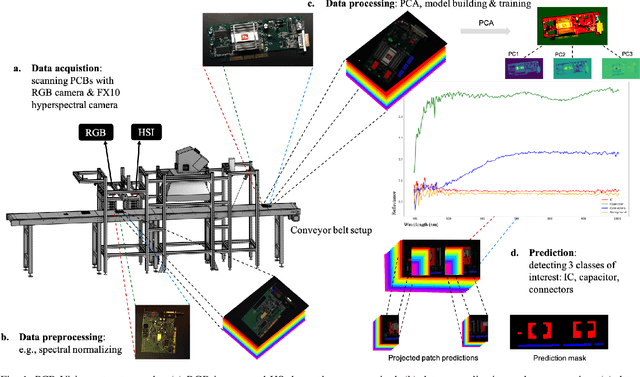


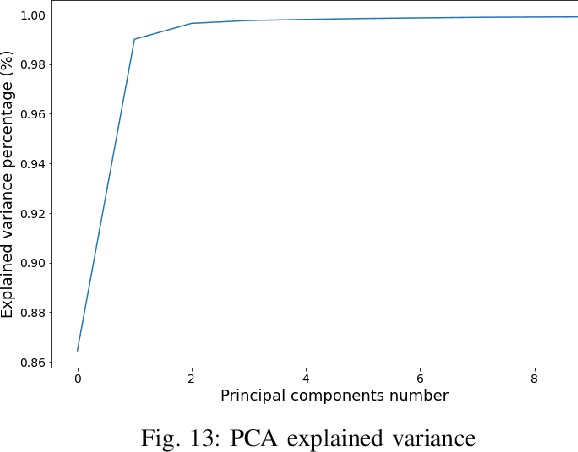
Addressing the critical theme of recycling electronic waste (E-waste), this contribution is dedicated to developing advanced automated data processing pipelines as a basis for decision-making and process control. Aligning with the broader goals of the circular economy and the United Nations (UN) Sustainable Development Goals (SDG), our work leverages non-invasive analysis methods utilizing RGB and hyperspectral imaging data to provide both quantitative and qualitative insights into the E-waste stream composition for optimizing recycling efficiency. In this paper, we introduce 'PCB-Vision'; a pioneering RGB-hyperspectral printed circuit board (PCB) benchmark dataset, comprising 53 RGB images of high spatial resolution paired with their corresponding high spectral resolution hyperspectral data cubes in the visible and near-infrared (VNIR) range. Grounded in open science principles, our dataset provides a comprehensive resource for researchers through high-quality ground truths, focusing on three primary PCB components: integrated circuits (IC), capacitors, and connectors. We provide extensive statistical investigations on the proposed dataset together with the performance of several state-of-the-art (SOTA) models, including U-Net, Attention U-Net, Residual U-Net, LinkNet, and DeepLabv3+. By openly sharing this multi-scene benchmark dataset along with the baseline codes, we hope to foster transparent, traceable, and comparable developments of advanced data processing across various scientific communities, including, but not limited to, computer vision and remote sensing. Emphasizing our commitment to supporting a collaborative and inclusive scientific community, all materials, including code, data, ground truth, and masks, will be accessible at https://github.com/hifexplo/PCBVision.
A Multisensor Hyperspectral Benchmark Dataset For Unmixing of Intimate Mixtures
Aug 30, 2023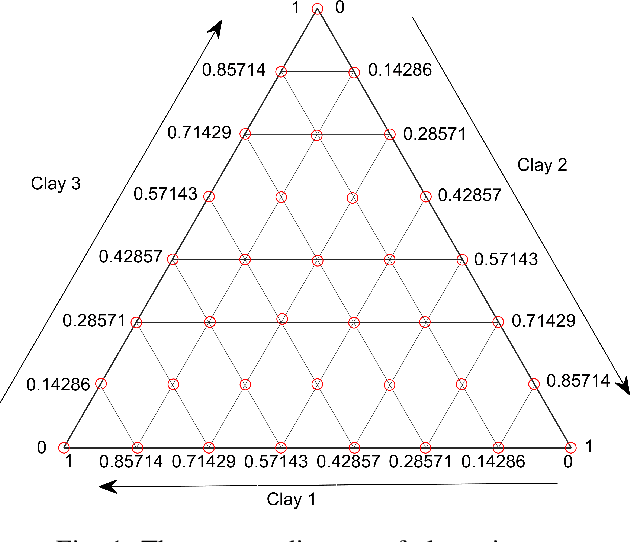
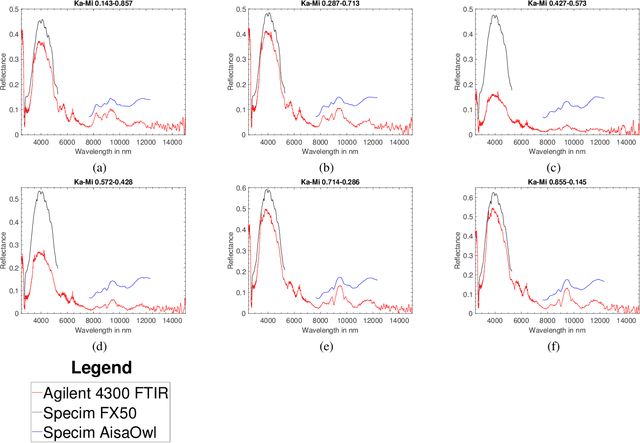
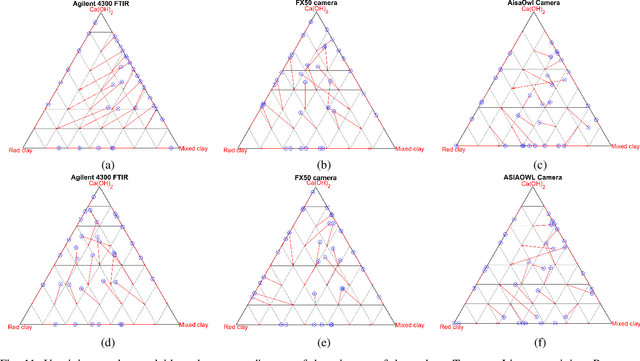
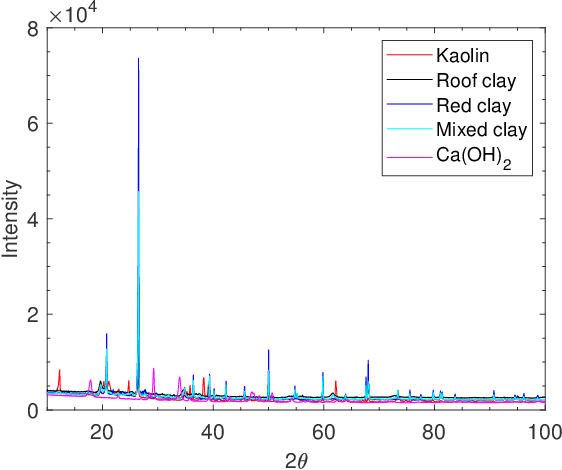
Optical hyperspectral cameras capture the spectral reflectance of materials. Since many materials behave as heterogeneous intimate mixtures with which each photon interacts differently, the relationship between spectral reflectance and material composition is very complex. Quantitative validation of spectral unmixing algorithms requires high-quality ground truth fractional abundance data, which are very difficult to obtain. In this work, we generated a comprehensive laboratory ground truth dataset of intimately mixed mineral powders. For this, five clay powders (Kaolin, Roof clay, Red clay, mixed clay, and Calcium hydroxide) were mixed homogeneously to prepare 325 samples of 60 binary, 150 ternary, 100 quaternary, and 15 quinary mixtures. Thirteen different hyperspectral sensors have been used to acquire the reflectance spectra of these mixtures in the visible, near, short, mid, and long-wavelength infrared regions (350-15385) nm. {\color{black} Overlaps in wavelength regions due to the operational ranges of each sensor} and variations in acquisition conditions {\color{black} resulted in} a large amount of spectral variability. Ground truth composition is given by construction, but to verify that the generated samples are sufficiently homogeneous, XRD and XRF elemental analysis is performed. We believe these data will be beneficial for validating advanced methods for nonlinear unmixing and material composition estimation, including studying spectral variability and training supervised unmixing approaches. The datasets can be downloaded from the following link: https://github.com/VisionlabUA/Multisensor_datasets.
Tinto: Multisensor Benchmark for 3D Hyperspectral Point Cloud Segmentation in the Geosciences
May 17, 2023



The increasing use of deep learning techniques has reduced interpretation time and, ideally, reduced interpreter bias by automatically deriving geological maps from digital outcrop models. However, accurate validation of these automated mapping approaches is a significant challenge due to the subjective nature of geological mapping and the difficulty in collecting quantitative validation data. Additionally, many state-of-the-art deep learning methods are limited to 2D image data, which is insufficient for 3D digital outcrops, such as hyperclouds. To address these challenges, we present Tinto, a multi-sensor benchmark digital outcrop dataset designed to facilitate the development and validation of deep learning approaches for geological mapping, especially for non-structured 3D data like point clouds. Tinto comprises two complementary sets: 1) a real digital outcrop model from Corta Atalaya (Spain), with spectral attributes and ground-truth data, and 2) a synthetic twin that uses latent features in the original datasets to reconstruct realistic spectral data (including sensor noise and processing artifacts) from the ground-truth. The point cloud is dense and contains 3,242,964 labeled points. We used these datasets to explore the abilities of different deep learning approaches for automated geological mapping. By making Tinto publicly available, we hope to foster the development and adaptation of new deep learning tools for 3D applications in Earth sciences. The dataset can be accessed through this link: https://doi.org/10.14278/rodare.2256.