 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized 3D Scene Generation for Generalizable Self-supervised Pre-training
Jun 07, 2023Capturing and labeling real-world 3D data is laborious and time-consuming, which makes it costly to train strong 3D models. To address this issue, previous works generate randomized 3D scenes and pre-train models on generated data. Although the pre-trained models gain promising performance boosts, previous works have two major shortcomings. First, they focus on only one downstream task (i.e., object detection). Second, a fair comparison of generated data is still lacking. In this work, we systematically compare data generation methods using a unified setup. To clarify the generalization of the pre-trained models, we evaluate their performance in multiple tasks (e.g., object detection and semantic segmentation) and with different pre-training methods (e.g., masked autoencoder and contrastive learning). Moreover, we propose a new method to generate 3D scenes with spherical harmonics. It surpasses the previous formula-driven method with a clear margin and achieves on-par results with methods using real-world scans and CAD models.
Applying Plain Transformers to Real-World Point Clouds
Mar 04, 2023Due to the lack of inductive bias, transformer-based models usually require a large amount of training data. The problem is especially concerning in 3D vision, as 3D data are harder to acquire and annotate. To overcome this problem, previous works modify the architecture of transformers to incorporate inductive biases by applying, e.g., local attention and down-sampling. Although they have achieved promising results, earlier works on transformers for point clouds have two issues. First, the power of plain transformers is still under-explored. Second, they focus on simple and small point clouds instead of complex real-world ones. This work revisits the plain transformers in real-world point cloud understanding. We first take a closer look at some fundamental components of plain transformers, e.g., patchifier and positional embedding, for both efficiency and performance. To close the performance gap due to the lack of inductive bias and annotated data, we investigate self-supervised pre-training with masked autoencoder (MAE). Specifically, we propose drop patch, which prevents information leakage and significantly improves the effectiveness of MAE. Our models achieve SOTA results in semantic segmentation on the S3DIS dataset and object detection on the ScanNet dataset with lower computational costs. Our work provides a new baseline for future research on transformers for point clouds.
A Closer Look at Invariances in Self-supervised Pre-training for 3D Vision
Jul 13, 2022
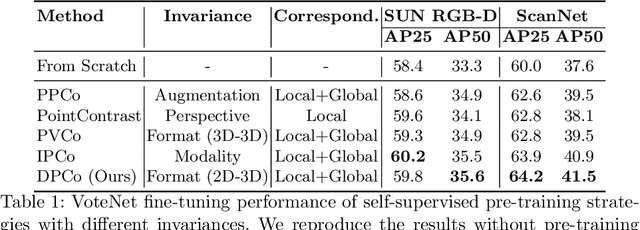
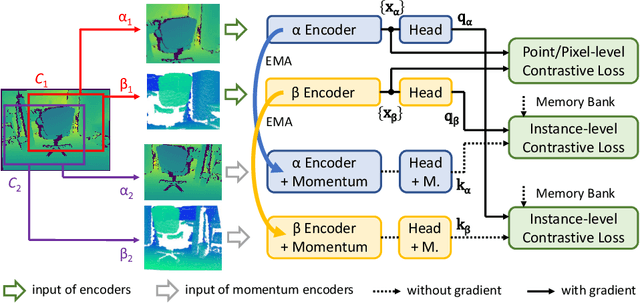
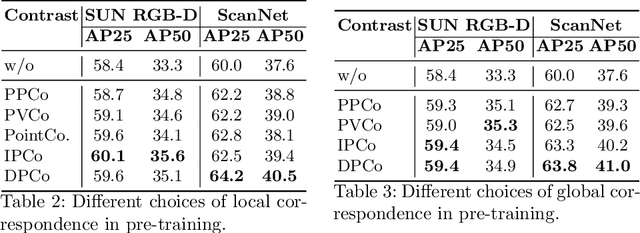
Self-supervised pre-training for 3D vision has drawn increasing research interest in recent years. In order to learn informative representations, a lot of previous works exploit invariances of 3D features, e.g., perspective-invariance between views of the same scene, modality-invariance between depth and RGB images, format-invariance between point clouds and voxels. Although they have achieved promising results, previous researches lack a systematic and fair comparison of these invariances. To address this issue, our work, for the first time, introduces a unified framework, under which various pre-training methods can be investigated. We conduct extensive experiments and provide a closer look at the contributions of different invariances in 3D pre-training. Also, we propose a simple but effective method that jointly pre-trains a 3D encoder and a depth map encoder using contrastive learning. Models pre-trained with our method gain significant performance boost in downstream tasks. For instance, a pre-trained VoteNet outperforms previous methods on SUN RGB-D and ScanNet object detection benchmarks with a clear margin.