 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TRAIL: Trust-Aware Client Scheduling for Semi-Decentralized Federated Learning
Dec 17, 2024


Due to the sensitivity of data, federated learning (FL) is employed to enable distributed machine learning while safeguarding data privacy and accommodating the requirements of various devices. However, in the context of semi-decentralized federated learning (SD-FL), clients' communication and training states are dynamic. This variability arises from local training fluctuations, heterogeneous data distributions, and intermittent client participation. Most existing studies primarily focus on stable client states, neglecting the dynamic challenges present in real-world scenarios. To tackle this issue, we propose a trust-aware client scheduling mechanism (TRAIL) that assesses client states and contributions, enhancing model training efficiency through selective client participation. Our focus is on a semi-decentralized federated learning framework where edge servers and clients train a shared global model using unreliable intra-cluster model aggregation and inter-cluster model consensus. First, we develop an adaptive hidden semi-Markov model (AHSMM) to estimate clients' communication states and contributions. Next, we address a client-server association optimization problem to minimize global training loss. Using convergence analysis, we propose a greedy client scheduling algorithm. Finally, our experiments conducted on real-world datasets demonstrate that TRAIL outperforms state-of-the-art baselines, achieving an improvement of 8.7\% in test accuracy and a reduction of 15.3\% in training loss.
Local Causal Structure Learning and its Discovery Between Type 2 Diabetes and Bone Mineral Density
Jun 27, 2020
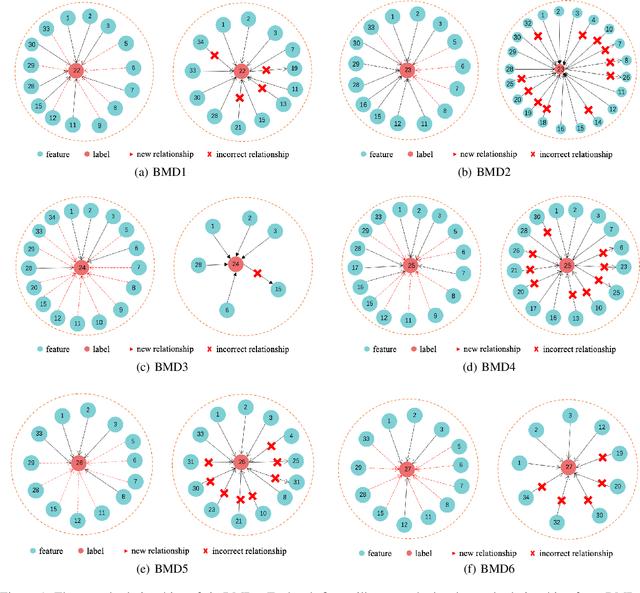
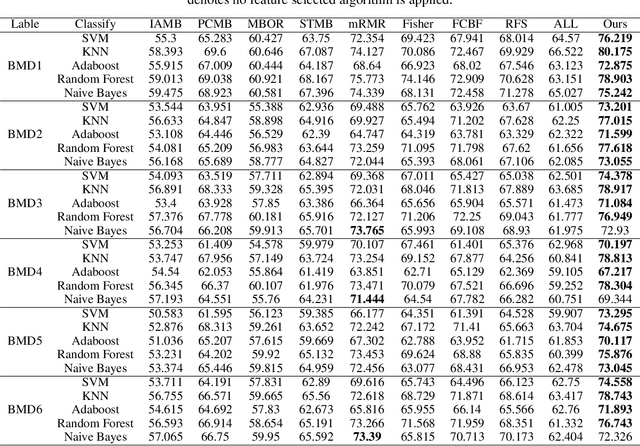
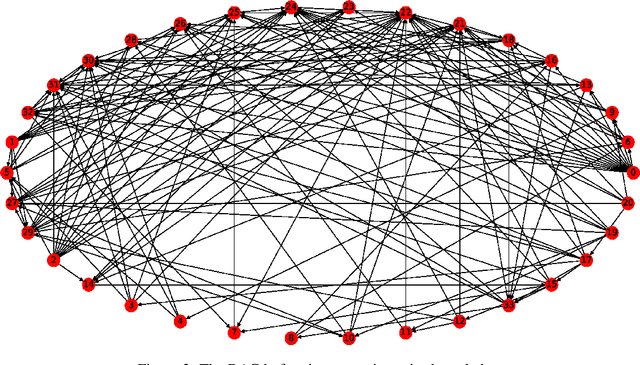
Type 2 diabetes (T2DM), one of the most prevalent chronic diseases, affects the glucose metabolism of the human body, which decreases the quantity of life and brings a heavy burden on social medical care. Patients with T2DM are more likely to suffer bone fragility fracture as diabetes affects bone mineral density (BMD). However, the discovery of the determinant factors of BMD in a medical way is expensive and time-consuming. In this paper, we propose a novel algorithm, Prior-Knowledge-driven local Causal structure Learning (PKCL), to discover the underlying causal mechanism between BMD and its factors from the clinical data. Since there exist limited data but redundant prior knowledge for medicine, PKCL adequately utilize the prior knowledge to mine the local causal structure for the target relationship. Combining the medical prior knowledge with the discovered causal relationships, PKCL can achieve more reliable results without long-standing medical statistical experiments. Extensive experiments are conducted on a newly provided clinical data set. The experimental study of PKCL on the data is proved to highly corresponding with existing medical knowledge, which demonstrates the superiority and effectiveness of PKCL. To illustrate the importance of prior knowledge, the result of the algorithm without prior knowledge is also investigated.