 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCross: Intertemporal Federated Learning Under Evolutionary Games
Dec 22, 2024



Federated Learning (FL) mitigates privacy leakage in decentralized machine learning by allowing multiple clients to train collaboratively locally. However, dynamic mobile networks with high mobility, intermittent connectivity, and bandwidth limitation severely hinder model updates to the cloud server. Although previous studies have typically addressed user mobility issue through task reassignment or predictive modeling, frequent migrations may result in high communication overhead. Overcoming this obstacle involves not only dealing with resource constraints, but also finding ways to mitigate the challenges posed by user migrations. We therefore propose an intertemporal incentive framework, FedCross, which ensures the continuity of FL tasks by migrating interrupted training tasks to feasible mobile devices. Specifically, FedCross comprises two distinct stages. In Stage 1, we address the task allocation problem across regions under resource constraints by employing a multi-objective migration algorithm to quantify the optimal task receivers. Moreover, we adopt evolutionary game theory to capture the dynamic decision-making of users, forecasting the evolution of user proportions across different regions to mitigate frequent migrations. In Stage 2, we utilize a procurement auction mechanism to allocate rewards among base stations, ensuring that those providing high-quality models receive optimal compensation. This approach incentivizes sustained user participation, thereby ensuring the overall feasibility of FedCross. Finally, experimental results validate the theoretical soundness of FedCross and demonstrate its significant reduction in communication overhead.
Mean Field Equilibrium in Multi-Armed Bandit Game with Continuous Reward
May 08, 2021

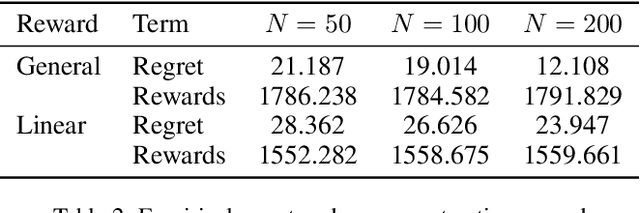
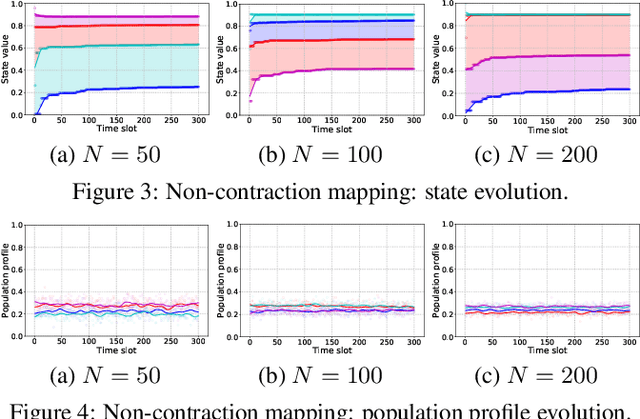
Mean field game facilitates analyzing multi-armed bandit (MAB) for a large number of agents by approximating their interactions with an average effect. Existing mean field models for multi-agent MAB mostly assume a binary reward function, which leads to tractable analysis but is usually not applicable in practical scenarios. In this paper, we study the mean field bandit game with a continuous reward function. Specifically, we focus on deriving the existence and uniqueness of mean field equilibrium (MFE), thereby guaranteeing the asymptotic stability of the multi-agent system. To accommodate the continuous reward function, we encode the learned reward into an agent state, which is in turn mapped to its stochastic arm playing policy and updated using realized observations. We show that the state evolution is upper semi-continuous, based on which the existence of MFE is obtained. As the Markov analysis is mainly for the case of discrete state, we transform the stochastic continuous state evolution into a deterministic ordinary differential equation (ODE). On this basis, we can characterize a contraction mapping for the ODE to ensure a unique MFE for the bandit game. Extensive evaluations validate our MFE characterization, and exhibit tight empirical regret of the MAB problem.