 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Pre-training with Topology- and Spatiality-aware Masked Autoencoders for 3D Medical Image Segmentation
Paper and Code
Jun 15, 2024
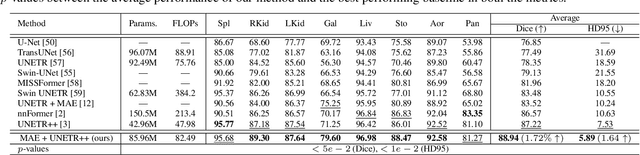
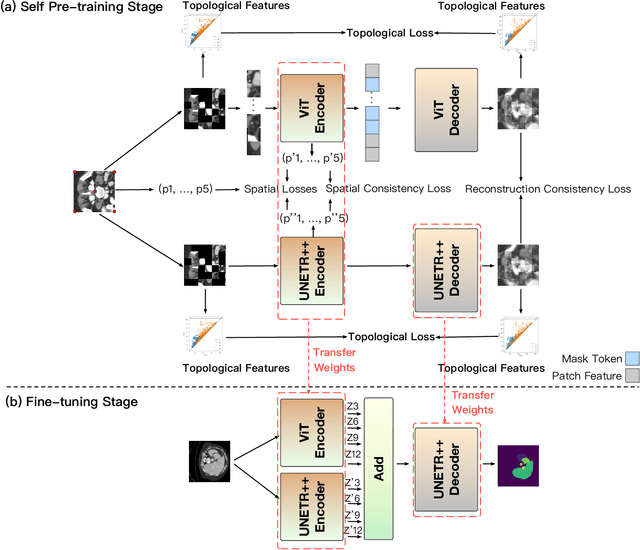

Masked Autoencoders (MAEs) have been shown to be effective in pre-training Vision Transformers (ViTs) for natural and medical image analysis problems. By reconstructing missing pixel/voxel information in visible patches, a ViT encoder can aggregate contextual information for downstream tasks. But, existing MAE pre-training methods, which were specifically developed with the ViT architecture, lack the ability to capture geometric shape and spatial information, which is critical for medical image segmentation tasks. In this paper, we propose a novel extension of known MAEs for self pre-training (i.e., models pre-trained on the same target dataset) for 3D medical image segmentation. (1) We propose a new topological loss to preserve geometric shape information by computing topological signatures of both the input and reconstructed volumes, learning geometric shape information. (2) We introduce a pre-text task that predicts the positions of the centers and eight corners of 3D crops, enabling the MAE to aggregate spatial information. (3) We extend the MAE pre-training strategy to a hybrid state-of-the-art (SOTA) medical image segmentation architecture and co-pretrain it alongside the ViT. (4) We develop a fine-tuned model for downstream segmentation tasks by complementing the pre-trained ViT encoder with our pre-trained SOTA model. Extensive experiments on five public 3D segmentation datasets show the effectiveness of our new approach.