 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining non-IID Data in Federated Learning for Computer Vision Tasks: Migrating from Labels to Embeddings for Task-Specific Data Distributions
Paper and Code


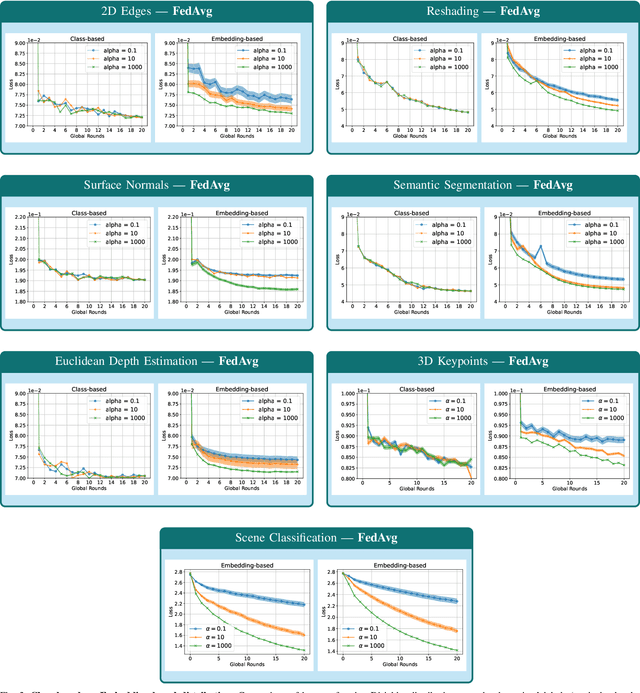

Federated Learning (FL) represents a paradigm shift in distributed machine learning (ML), enabling clients to train models collaboratively while keeping their raw data private. This paradigm shift from traditional centralized ML introduces challenges due to the non-iid (non-independent and identically distributed) nature of data across clients, significantly impacting FL's performance. Existing literature, predominantly model data heterogeneity by imposing label distribution skew across clients. In this paper, we show that label distribution skew fails to fully capture the real-world data heterogeneity among clients in computer vision tasks beyond classification. Subsequently, we demonstrate that current approaches overestimate FL's performance by relying on label/class distribution skew, exposing an overlooked gap in the literature. By utilizing pre-trained deep neural networks to extract task-specific data embeddings, we define task-specific data heterogeneity through the lens of each vision task and introduce a new level of data heterogeneity called embedding-based data heterogeneity. Our methodology involves clustering data points based on embeddings and distributing them among clients using the Dirichlet distribution. Through extensive experiments, we evaluate the performance of different FL methods under our revamped notion of data heterogeneity, introducing new benchmark performance measures to the literature. We further unveil a series of open research directions that can be pursued.