 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3TU-Net: Structured Convolution and Superpixel Transformer for Lung Nodule Segmentation
Paper and Code
Nov 19, 2024

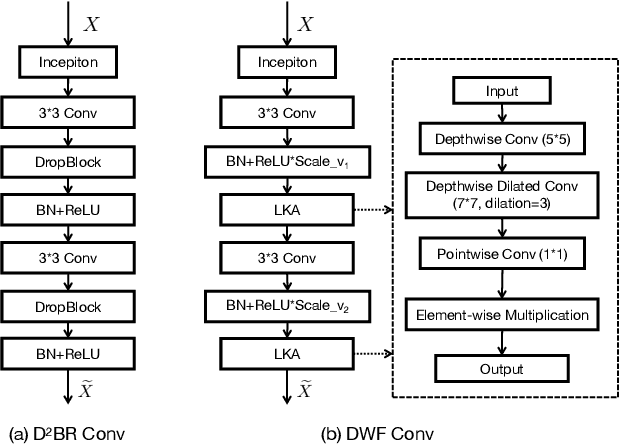
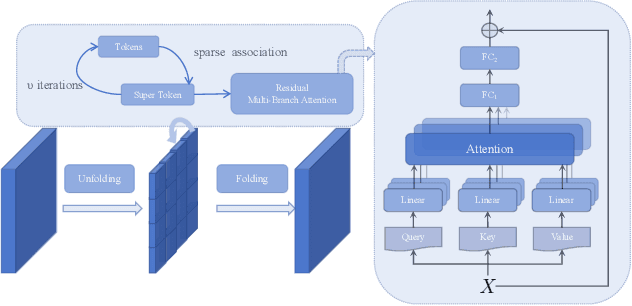
The irregular and challenging characteristics of lung adenocarcinoma nodules in computed tomography (CT) images complicate staging diagnosis, making accurate segmentation critical for clinicians to extract detailed lesion information. In this study, we propose a segmentation model, S3TU-Net, which integrates multi-dimensional spatial connectors and a superpixel-based visual transformer. S3TU-Net is built on a multi-view CNN-Transformer hybrid architecture, incorporating superpixel algorithms, structured weighting, and spatial shifting techniques to achieve superior segmentation performance. The model leverages structured convolution blocks (DWF-Conv/D2BR-Conv) to extract multi-scale local features while mitigating overfitting. To enhance multi-scale feature fusion, we introduce the S2-MLP Link, integrating spatial shifting and attention mechanisms at the skip connections. Additionally, the residual-based superpixel visual transformer (RM-SViT) effectively merges global and local features by employing sparse correlation learning and multi-branch attention to capture long-range dependencies, with residual connections enhancing stability and computational efficiency. Experimental results on the LIDC-IDRI dataset demonstrate that S3TU-Net achieves a DSC, precision, and IoU of 89.04%, 90.73%, and 90.70%, respectively. Compared to recent methods, S3TU-Net improves DSC by 4.52% and sensitivity by 3.16%, with other metrics showing an approximate 2% increase. In addition to comparison and ablation studies, we validated the generalization ability of our model on the EPDB private dataset, achieving a DSC of 86.40%.