 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Speaker-specific Features in Speaker Representations
Jan 09, 2025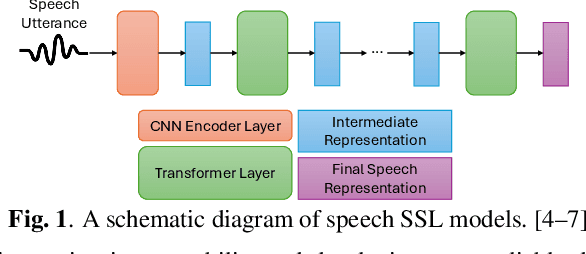
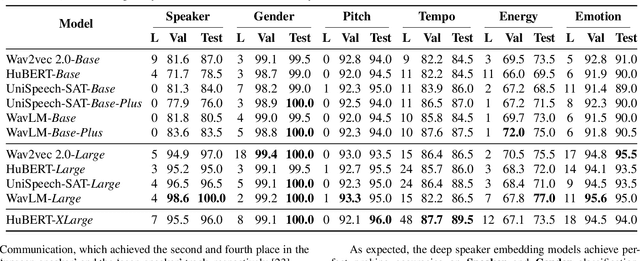
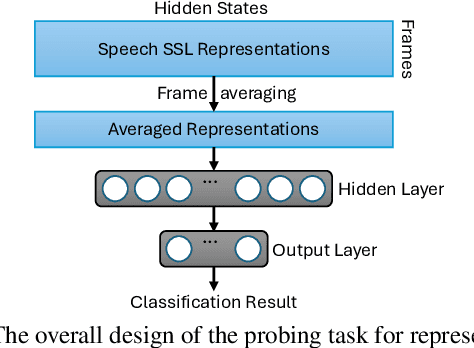
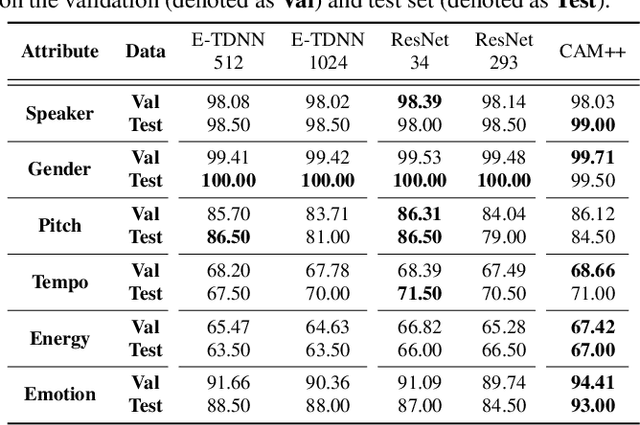
This study explores speaker-specific features encoded in speaker embeddings and intermediate layers of speech self-supervised learning (SSL) models. By utilising a probing method, we analyse features such as pitch, tempo, and energy across prominent speaker embedding models and speech SSL models, including HuBERT, WavLM, and Wav2vec 2.0. The results reveal that speaker embeddings like CAM++ excel in energy classification, while speech SSL models demonstrate superior performance across multiple features due to their hierarchical feature encoding. Intermediate layers effectively capture a mix of acoustic and para-linguistic information, with deeper layers refining these representations. This investigation provides insights into model design and highlights the potential of these representations for downstream applications, such as speaker verification and text-to-speech synthesis, while laying the groundwork for exploring additional features and advanced probing methods.