 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Compression for DNN-Based Text-Independent Speaker Verification Using Weight Quantization
Paper and Code
Nov 14, 2022


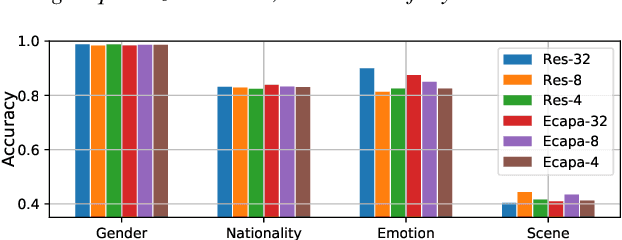
DNN-based models achieve high performance in the speaker verification (SV) task with substantial computation costs. The model size is an essential concern in applying models on resource-constrained devices, while model compression for SV models has not been studied extensively in previous works. Weight quantization is exploited to compress DNN-based speaker embedding extraction models in this paper. Uniform and Powers-of-Two quantization are utilized in the experiments. The results on VoxCeleb show that the weight quantization can decrease the size of ECAPA-TDNN and ResNet by 4 times with insignificant performance decline. The quantized 4-bit ResNet achieves similar performance to the original model with an 8 times smaller size. We empirically show that the performance of ECAPA-TDNN is more sensitive than ResNet to quantization due to the difference in weight distribution. The experiments on CN-Celeb also demonstrate that quantized models are robust for SV in the language mismatch scenario.