 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Noise Suppression and Discriminative Mutual Interaction for Robust Audio-Visual Segmentation
Mar 15, 2026The ability to capture and segment sounding objects in dynamic visual scenes is crucial for the development of Audio-Visual Segmentation (AVS) tasks. While significant progress has been made in this area, the interaction between audio and visual modalities still requires further exploration. In this work, we aim to answer the following questions: How can a model effectively suppress audio noise while enhancing relevant audio information? How can we achieve discriminative interaction between the audio and visual modalities? To this end, we propose SDAVS, equipped with the Selective Noise-Resilient Processor (SNRP) module and the Discriminative Audio-Visual Mutual Fusion (DAMF) strategy. The proposed SNRP mitigates audio noise interference by selectively emphasizing relevant auditory cues, while DAMF ensures more consistent audio-visual representations. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on benchmark AVS datasets, especially in multi-source and complex scenes. \textit{The code and model are available at https://github.com/happylife-pk/SDAVS}.
Utilizing Earth Foundation Models to Enhance the Simulation Performance of Hydrological Models with AlphaEarth Embeddings
Jan 04, 2026Predicting river flow in places without streamflow records is challenging because basins respond differently to climate, terrain, vegetation, and soils. Traditional basin attributes describe some of these differences, but they cannot fully represent the complexity of natural environments. This study examines whether AlphaEarth Foundation embeddings, which are learned from large collections of satellite images rather than designed by experts, offer a more informative way to describe basin characteristics. These embeddings summarize patterns in vegetation, land surface properties, and long-term environmental dynamics. We find that models using them achieve higher accuracy when predicting flows in basins not used for training, suggesting that they capture key physical differences more effectively than traditional attributes. We further investigate how selecting appropriate donor basins influences prediction in ungauged regions. Similarity based on the embeddings helps identify basins with comparable environmental and hydrological behavior, improving performance, whereas adding many dissimilar basins can reduce accuracy. The results show that satellite-informed environmental representations can strengthen hydrological forecasting and support the development of models that adapt more easily to different landscapes.
P3Net: Progressive and Periodic Perturbation for Semi-Supervised Medical Image Segmentation
May 21, 2025Perturbation with diverse unlabeled data has proven beneficial for semi-supervised medical image segmentation (SSMIS). While many works have successfully used various perturbation techniques, a deeper understanding of learning perturbations is needed. Excessive or inappropriate perturbation can have negative effects, so we aim to address two challenges: how to use perturbation mechanisms to guide the learning of unlabeled data through labeled data, and how to ensure accurate predictions in boundary regions. Inspired by human progressive and periodic learning, we propose a progressive and periodic perturbation mechanism (P3M) and a boundary-focused loss. P3M enables dynamic adjustment of perturbations, allowing the model to gradually learn them. Our boundary-focused loss encourages the model to concentrate on boundary regions, enhancing sensitivity to intricate details and ensuring accurate predictions. Experimental results demonstrate that our method achieves state-of-the-art performance on two 2D and 3D datasets. Moreover, P3M is extendable to other methods, and the proposed loss serves as a universal tool for improving existing methods, highlighting the scalability and applicability of our approach.
DefMamba: Deformable Visual State Space Model
Apr 08, 2025



Recently, state space models (SSM), particularly Mamba, have attracted significant attention from scholars due to their ability to effectively balance computational efficiency and performance. However, most existing visual Mamba methods flatten images into 1D sequences using predefined scan orders, which results the model being less capable of utilizing the spatial structural information of the image during the feature extraction process. To address this issue, we proposed a novel visual foundation model called DefMamba. This model includes a multi-scale backbone structure and deformable mamba (DM) blocks, which dynamically adjust the scanning path to prioritize important information, thus enhancing the capture and processing of relevant input features. By combining a deformable scanning(DS) strategy, this model significantly improves its ability to learn image structures and detects changes in object details. Numerous experiments have shown that DefMamba achieves state-of-the-art performance in various visual tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is open source on DefMamba.
CNN-Transformer Rectified Collaborative Learning for Medical Image Segmentation
Aug 27, 2024



Automatic and precise medical image segmentation (MIS) is of vital importance for clinical diagnosis and analysis. Current MIS methods mainly rely on the convolutional neural network (CNN) or self-attention mechanism (Transformer) for feature modeling. However, CNN-based methods suffer from the inaccurate localization owing to the limited global dependency while Transformer-based methods always present the coarse boundary for the lack of local emphasis. Although some CNN-Transformer hybrid methods are designed to synthesize the complementary local and global information for better performance, the combination of CNN and Transformer introduces numerous parameters and increases the computation cost. To this end, this paper proposes a CNN-Transformer rectified collaborative learning (CTRCL) framework to learn stronger CNN-based and Transformer-based models for MIS tasks via the bi-directional knowledge transfer between them. Specifically, we propose a rectified logit-wise collaborative learning (RLCL) strategy which introduces the ground truth to adaptively select and rectify the wrong regions in student soft labels for accurate knowledge transfer in the logit space. We also propose a class-aware feature-wise collaborative learning (CFCL) strategy to achieve effective knowledge transfer between CNN-based and Transformer-based models in the feature space by granting their intermediate features the similar capability of category perception. Extensive experiments on three popular MIS benchmarks demonstrate that our CTRCL outperforms most state-of-the-art collaborative learning methods under different evaluation metrics.
CriDiff: Criss-cross Injection Diffusion Framework via Generative Pre-train for Prostate Segmentation
Jun 20, 2024



Recently, the Diffusion Probabilistic Model (DPM)-based methods have achieved substantial success in the field of medical image segmentation. However, most of these methods fail to enable the diffusion model to learn edge features and non-edge features effectively and to inject them efficiently into the diffusion backbone. Additionally, the domain gap between the images features and the diffusion model features poses a great challenge to prostate segmentation. In this paper, we proposed CriDiff, a two-stage feature injecting framework with a Crisscross Injection Strategy (CIS) and a Generative Pre-train (GP) approach for prostate segmentation. The CIS maximizes the use of multi-level features by efficiently harnessing the complementarity of high and low-level features. To effectively learn multi-level of edge features and non-edge features, we proposed two parallel conditioners in the CIS: the Boundary Enhance Conditioner (BEC) and the Core Enhance Conditioner (CEC), which discriminatively model the image edge regions and non-edge regions, respectively. Moreover, the GP approach eases the inconsistency between the images features and the diffusion model without adding additional parameters. Extensive experiments on four benchmark datasets demonstrate the effectiveness of the proposed method and achieve state-of-the-art performance on four evaluation metrics.
MFNet: Multi-filter Directive Network for Weakly Supervised Salient Object Detection
Dec 03, 2021

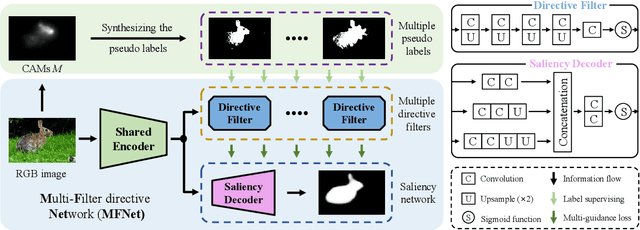

Weakly supervised salient object detection (WSOD) targets to train a CNNs-based saliency network using only low-cost annotations. Existing WSOD methods take various techniques to pursue single "high-quality" pseudo label from low-cost annotations and then develop their saliency networks. Though these methods have achieved good performance, the generated single label is inevitably affected by adopted refinement algorithms and shows prejudiced characteristics which further influence the saliency networks. In this work, we introduce a new multiple-pseudo-label framework to integrate more comprehensive and accurate saliency cues from multiple labels, avoiding the aforementioned problem. Specifically, we propose a multi-filter directive network (MFNet) including a saliency network as well as multiple directive filters. The directive filter (DF) is designed to extract and filter more accurate saliency cues from the noisy pseudo labels. The multiple accurate cues from multiple DFs are then simultaneously propagated to the saliency network with a multi-guidance loss. Extensive experiments on five datasets over four metrics demonstrate that our method outperforms all the existing congeneric methods. Moreover, it is also worth noting that our framework is flexible enough to apply to existing methods and improve their performance.
To be Critical: Self-Calibrated Weakly Supervised Learning for Salient Object Detection
Sep 04, 2021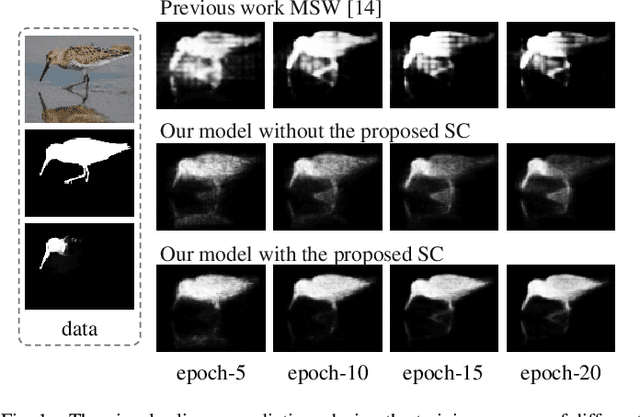
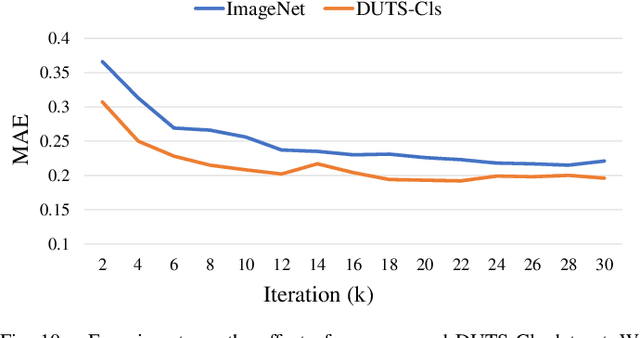
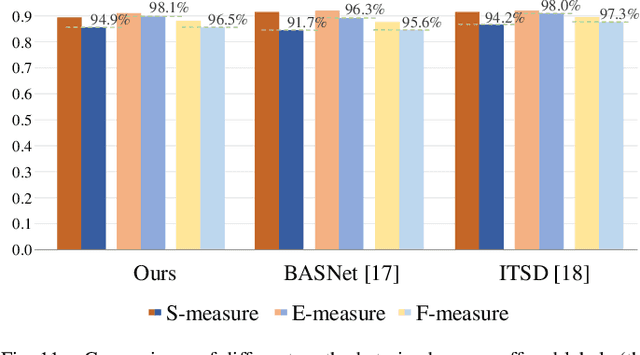
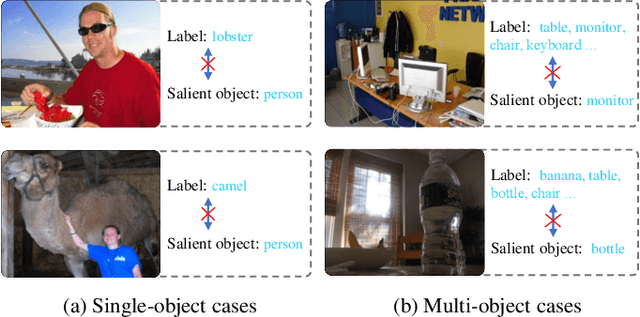
Weakly-supervised salient object detection (WSOD) aims to develop saliency models using image-level annotations. Despite of the success of previous works, explorations on an effective training strategy for the saliency network and accurate matches between image-level annotations and salient objects are still inadequate. In this work, 1) we propose a self-calibrated training strategy by explicitly establishing a mutual calibration loop between pseudo labels and network predictions, liberating the saliency network from error-prone propagation caused by pseudo labels. 2) we prove that even a much smaller dataset (merely 1.8% of ImageNet) with well-matched annotations can facilitate models to achieve better performance as well as generalizability. This sheds new light on the development of WSOD and encourages more contributions to the community. Comprehensive experiments demonstrate that our method outperforms all the existing WSOD methods by adopting the self-calibrated strategy only. Steady improvements are further achieved by training on the proposed dataset. Additionally, our method achieves 94.7% of the performance of fully-supervised methods on average. And what is more, the fully supervised models adopting our predicted results as "ground truths" achieve successful results (95.6% for BASNet and 97.3% for ITSD on F-measure), while costing only 0.32% of labeling time for pixel-level annotation.
Learning Multi-modal Information for Robust Light Field Depth Estimation
Apr 13, 2021
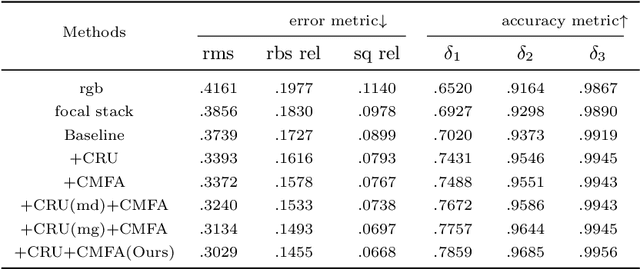
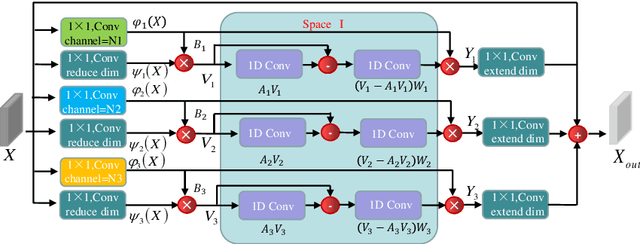
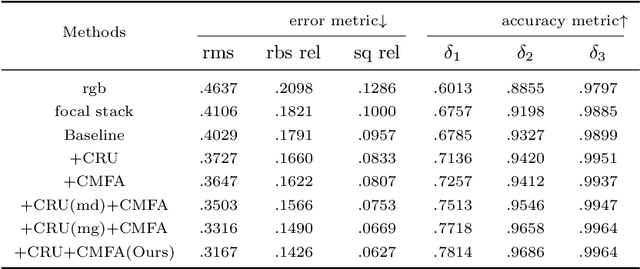
Light field data has been demonstrated to facilitate the depth estimation task. Most learning-based methods estimate the depth infor-mation from EPI or sub-aperture images, while less methods pay attention to the focal stack. Existing learning-based depth estimation methods from the focal stack lead to suboptimal performance because of the defocus blur. In this paper, we propose a multi-modal learning method for robust light field depth estimation. We first excavate the internal spatial correlation by designing a context reasoning unit which separately extracts comprehensive contextual information from the focal stack and RGB images. Then we integrate the contextual information by exploiting a attention-guide cross-modal fusion module. Extensive experiments demonstrate that our method achieves superior performance than existing representative methods on two light field datasets. Moreover, visual results on a mobile phone dataset show that our method can be widely used in daily life.
Dynamic Fusion Network For Light Field Depth Estimation
Apr 13, 2021
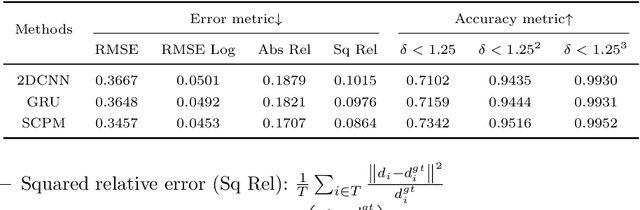
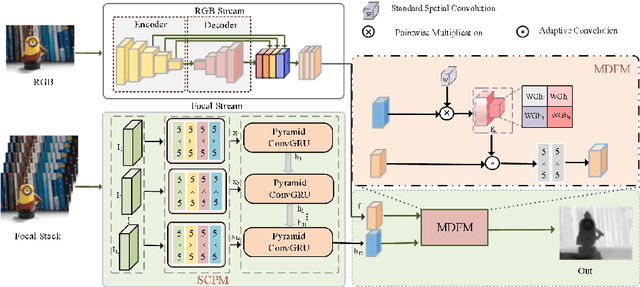
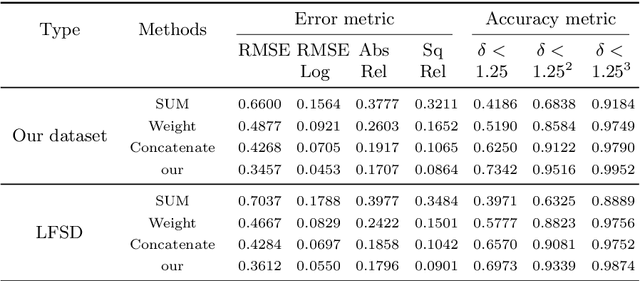
Focus based methods have shown promising results for the task of depth estimation. However, most existing focus based depth estimation approaches depend on maximal sharpness of the focal stack. Out of focus information in the focal stack poses challenges for this task. In this paper, we propose a dynamically multi modal learning strategy which incorporates RGB data and the focal stack in our framework. Our goal is to deeply excavate the spatial correlation in the focal stack by designing the spatial correlation perception module and dynamically fuse multi modal information between RGB data and the focal stack in a adaptive way by designing the multi modal dynamic fusion module. The success of our method is demonstrated by achieving the state of the art performance on two datasets. Furthermore, we test our network on a set of different focused images generated by a smart phone camera to prove that the proposed method not only broke the limitation of only using light field data, but also open a path toward practical applications of depth estimation on common consumer level cameras data.